隨著人工智慧(AI)技術的發展,視頻生成技術正快速進步,然而,如何提升 AI 生成視頻的品質,一直是技術專家關注的難題。為了解決這個問題,香港中文大學、清華大學及快手科技 聯合推出 VideoReward,這是一款基於 人類回饋(Human Feedback) 的 視頻生成獎勵模型。
VideoReward 的核心價值
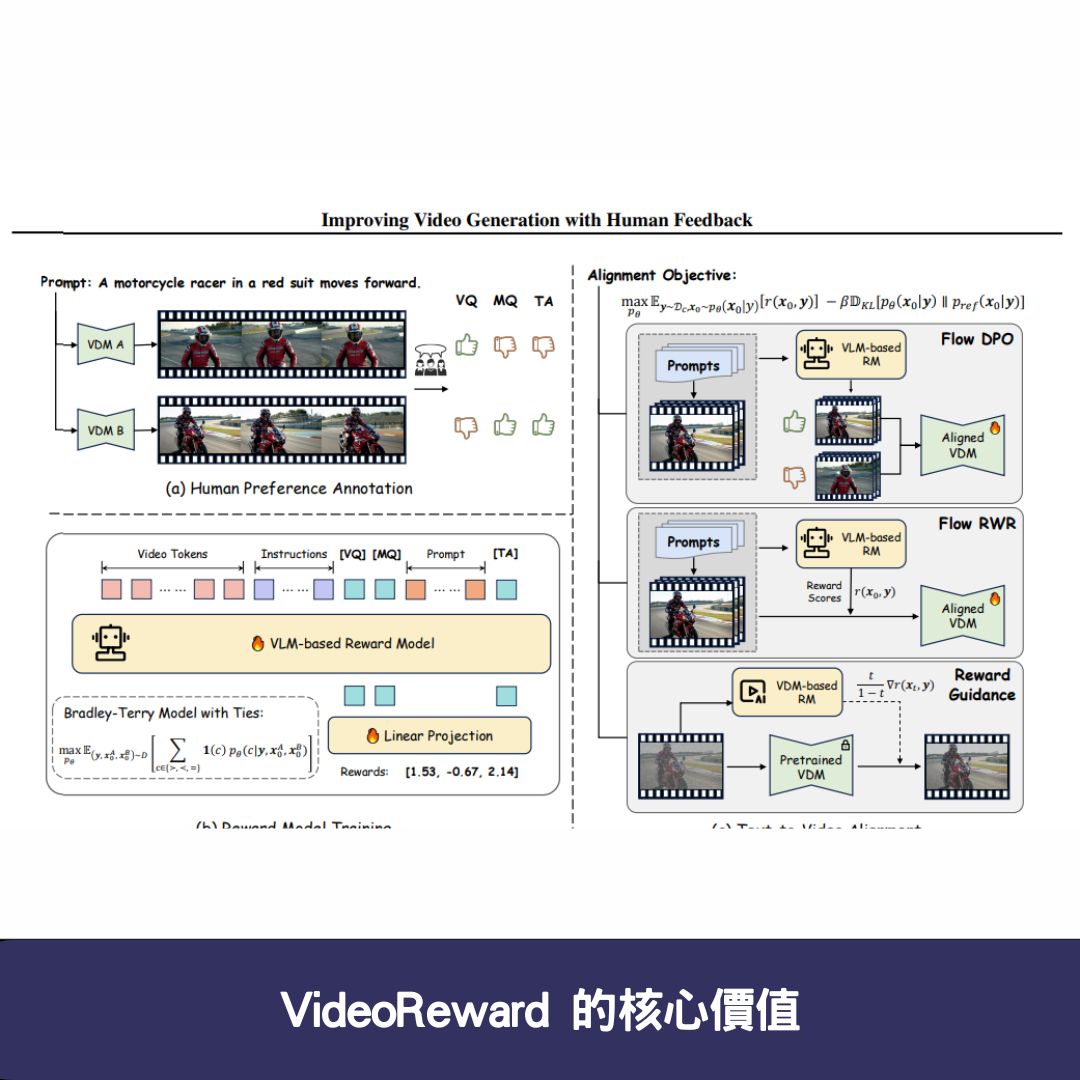
VideoReward 通過 大規模標註資料集 與 多維度獎勵機制,幫助 AI 模型自動優化視頻生成的品質,主要涵蓋三個關鍵維度:
- 視覺品質(VQ):確保生成的視頻在畫質、細節和清晰度上達到高標準。
- 運動品質(MQ):改善運動場景的流暢性與真實感,使 AI 生成的視頻更加自然。
- 文本對齊(TA):讓視頻內容與原始提示文本(Prompt)更精確地匹配,提高敘事一致性。
VideoReward 的最大亮點是 無需額外訓練 AI 模型,透過 強化學習與人類偏好標註,直接優化現有的視頻生成技術,大幅提升 AI 生成內容的品質與準確性。
VideoReward 的技術核心:三大對齊演算法解析
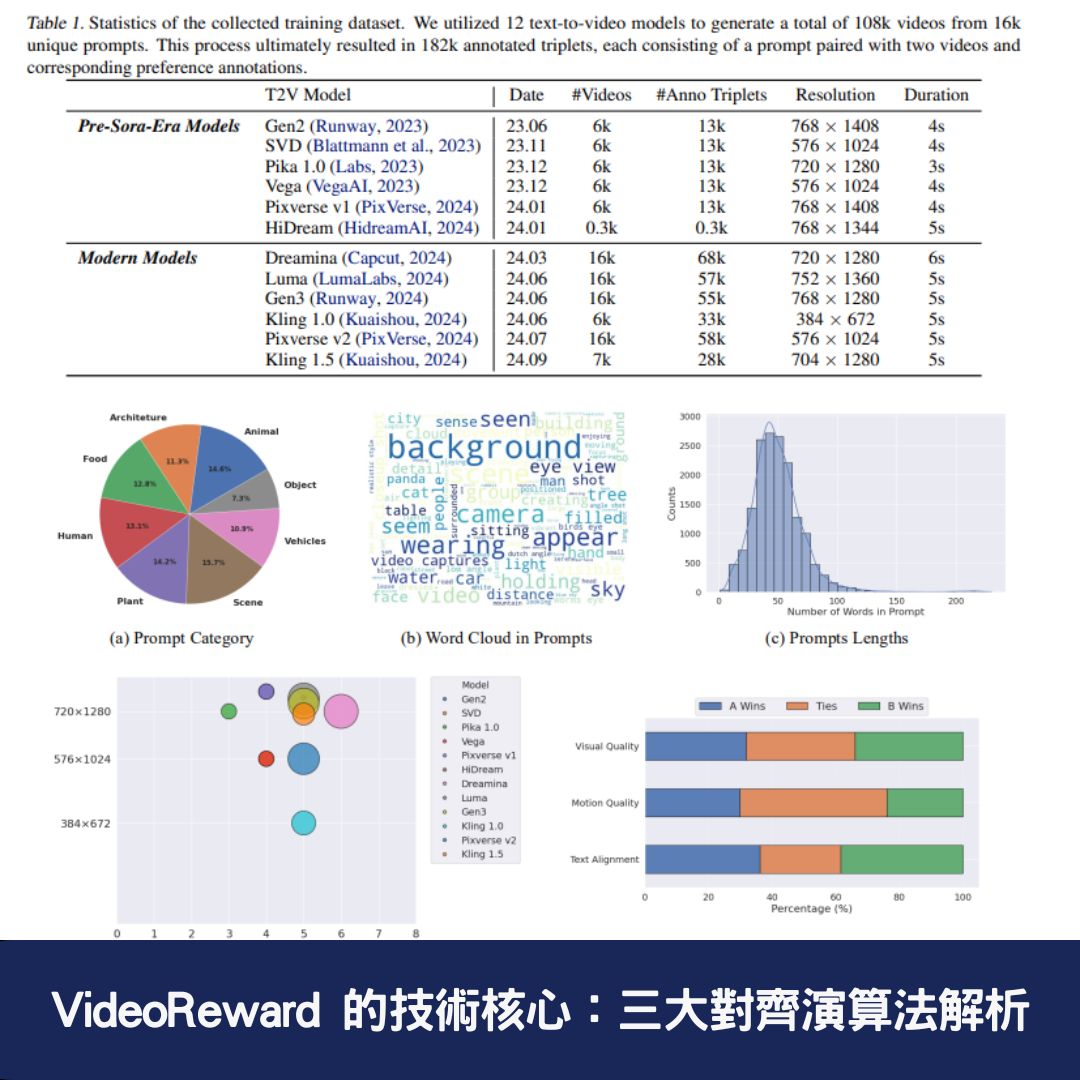
為了確保 AI 生成的視頻能夠達到更高品質,VideoReward 採用了 三種對齊演算法 來強化獎勵模型的效果:
1. Flow-DPO(直接偏好優化,Direct Preference Optimization)
這是一種 強化學習技術,可在訓練階段根據人類標註的偏好來調整 AI 模型,確保 AI 優先生成符合使用者需求的視頻。
2. Flow-RWR(獎勵加權回歸,Reward-Weighted Regression)
透過 獎勵加權機制 來微調 AI 生成的內容,使得每一個輸出結果都能更好地匹配人類回饋,確保視覺品質和運動流暢度的平衡。
3. Flow-NRG(雜訊視頻獎勵引導,Noise Reward Guidance)
這是一種 推理階段(Inference Phase) 的優化技術,允許使用者自訂不同目標的權重,例如 畫質優先、運動流暢度優先或文本對齊優先,滿足不同應用場景的需求。
這三種技術的結合,使 VideoReward 成為目前最具潛力的 AI 視頻生成獎勵模型。

VideoReward 的應用場景
1. AI 生成視頻品質優化
許多 AI 生成視頻的模型,如 Stable Video Diffusion(SVD) 或 Runway Gen-2,在生成視頻時仍然存在畫質下降、運動不流暢等問題。透過 VideoReward,這些問題可以有效改善,讓 AI 生成的視頻更加自然、生動。
2. 個性化視頻內容創作
使用者可以利用 VideoReward 的 Flow-NRG 技術 來自訂 AI 生成視頻的權重,根據不同需求調整畫質、運動流暢度和文本對齊度,打造個性化的 AI 生成內容。
3. 自動化視頻編輯與特效增強
影片創作者可以將 VideoReward 應用於 視頻後製與特效增強,使 AI 生成的內容更符合專業級標準,減少人工調整的時間。
4. AI 視頻檢索與推薦系統
在短影音平台(如 TikTok、Instagram Reels)或影音串流服務(如 Netflix、YouTube)中,VideoReward 可透過 人類回饋標註 提供更準確的視頻推薦,提高觀眾的觀看體驗。
VideoReward 的優勢
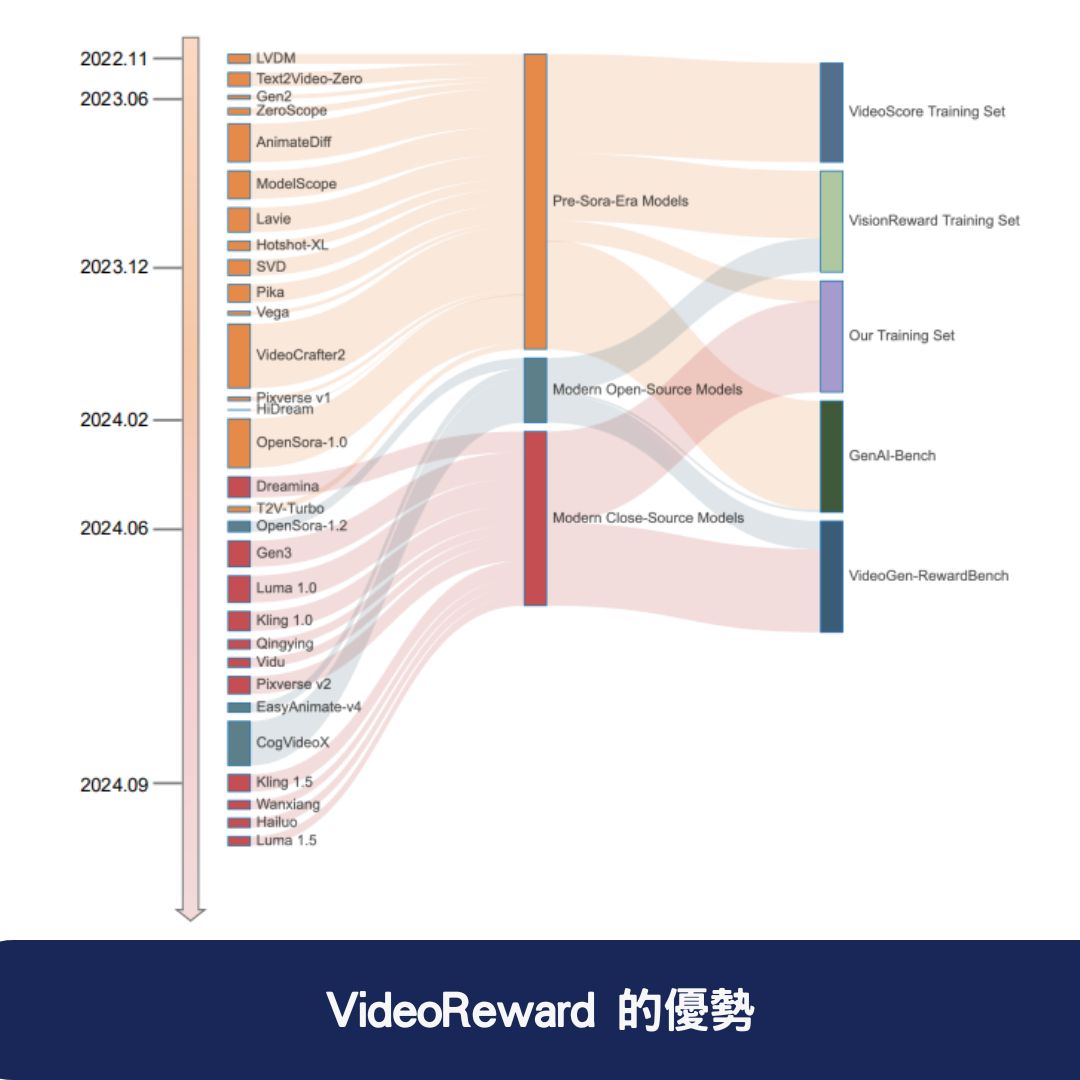
- 無需額外訓練 AI 模型:傳統的視頻生成優化技術往往需要進行額外的深度學習訓練,而 VideoReward 僅透過獎勵機制 來提升內容品質,大幅降低計算成本。
- 涵蓋多維度評估標準:傳統視頻獎勵模型通常僅關注畫質,而 VideoReward 則綜合考慮 視覺品質、運動品質與文本對齊,提升 AI 生成視頻的整體品質。
- 支援個性化視頻生成:透過 Flow-NRG 技術,使用者可以自訂視頻生成的目標權重,以滿足不同應用場景的需求。
- 適用於多種 AI 視頻生成技術:VideoReward 可無縫整合至目前主流的 AI 生成視頻模型,如 SVD、Runway Gen-2 等,提升 AI 生成視頻的準確性與可用性。
常見問題與解答(FAQ)
1. VideoReward 與其他視頻獎勵模型有何不同?
VideoReward 透過 人類回饋(Human Feedback) 與 多維度獎勵機制 來優化視頻生成,而無需額外訓練模型。它不僅關注 視覺品質(VQ),還涵蓋 運動品質(MQ) 和 文本對齊(TA),透過 Flow-DPO、Flow-RWR、Flow-NRG 等技術大幅提升視頻的真實感與流暢性。
2. VideoReward 的應用場景有哪些?
VideoReward 可用於 AI 生成視頻品質優化、視頻內容創作、個性化視頻推薦、AI 視頻檢索系統,甚至能用於 自動化編輯與視頻特效增強。這使其適用於短影音平台、廣告行業、電影製作等領域。
3. VideoReward 是否需要額外訓練 AI 模型?
不需要!VideoReward 不依賴額外的 AI 訓練,而是透過 獎勵模型與偏好數據集 來優化現有的視頻生成技術。這意味著它可以輕鬆整合到 現有的 AI 視頻生成框架(如 Stable Video Diffusion),無需進行額外的深度學習訓練,大幅降低技術門檻。
成為AI學習平台訂閱者

NT$300 / 1個月

NT$900 / 3個月

NT$3,000 / 12個月