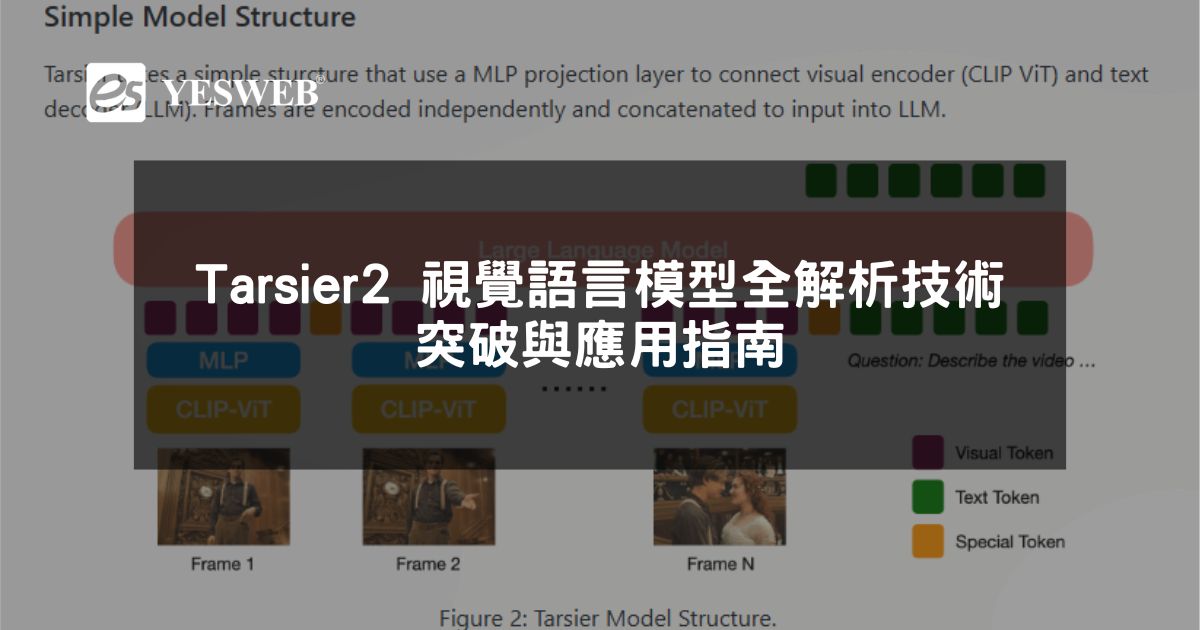
Tarsier2 是由位元組跳動(ByteDance)推出的最新一代大規模視覺語言模型(LVLM),專為理解和描述視頻內容而設計。這款模型能夠生成詳細且準確的視頻描述,在多種視頻理解任務中表現卓越,並在多項基準測試中超越了 GPT-4o 和 Gemini-1.5-Pro。
Tarsier2 的核心功能

1. 高品質的視頻描述
Tarsier2 具備強大的視頻內容解析能力,能夠自動生成豐富的視頻描述,涵蓋動作、場景、人物互動和情節發展。
2. 視頻問答(VQA)
該模型能夠回答關於視頻的各種問題,展現出強大的時空理解和推理能力。例如,它可以分析視頻內容,提供準確的背景資訊和事件細節。
3. 視頻事件定位
Tarsier2 具備先進的視頻定位功能,能夠精確標記特定事件在視頻中的發生時間,並支援多視頻段定位。
4. 幻覺測試與資訊真實性提升
Tarsier2 在訓練過程中通過優化策略顯著減少了幻覺現象,即生成錯誤或虛假的資訊,使其提供的視頻描述更加準確。
5. 多語言支援
該模型能夠生成多種語言的視頻描述,適用於全球市場,滿足不同語言環境下的應用需求。
Tarsier2 的技術優勢

1. 大規模預訓練數據
Tarsier2 在訓練時將數據量從 1100 萬條擴展至 4000 萬條視頻-文本對,提升了資料的豐富度與多樣性。這些數據來源於互聯網短視頻、電影解說、電視劇內容等,並由多模態 LLM 自動生成視頻描述與問答對。
2. 細粒度時間對齊監督微調(SFT)
模型訓練時引入 15 萬條高精度標註的視頻描述資料,並確保每條描述對應準確的時間戳,這顯著提高了視頻描述的準確性,並有效降低了幻覺現象的發生。
3. 直接偏好優化(DPO)訓練
Tarsier2 採用了直接偏好優化(DPO)技術,透過模型自動生成的正負樣本對來訓練偏好模型,使生成的描述更符合人類閱讀習慣,提高文本的自然度與可讀性。
Tarsier2 在基準測試中的表現
Tarsier2 在多項基準測試中表現優異,其中包括:
- DREAM-1K 基準測試:Tarsier2-7B 的 F1 分數比 GPT-4o 高 2.8%,比 Gemini-1.5-Pro 高 5.8%。
- 15 項公共基準測試:涵蓋視頻問答、視頻定位、幻覺測試與具身問答等領域,皆取得最佳結果。
Tarsier2 的應用場景

1. 高品質視頻內容描述
Tarsier2 能夠為不同類型的視頻自動生成豐富的文本描述,適用於內容標註、視頻索引與搜索引擎優化(SEO)。
2. 智能視頻問答(VQA)
該模型可以回答關於視頻內容的問題,適用於影片推薦系統、學術研究和互動式 AI 助手。
3. 視頻事件檢測與分析
Tarsier2 具備高度精確的時間對齊能力,能夠幫助使用者快速找到視頻中特定片段,適用於監控、體育分析與教育內容製作。
4. 降低視頻內容幻覺
在減少虛假資訊生成方面,Tarsier2 顯著優於其他 LVLM,適合應用於新聞摘要、知識庫建構與內容過濾。
5. 多語言視頻理解
支援多種語言的視頻描述生成,可用於國際市場的內容創作與翻譯。
Tarsier2 的技術資源
如果想要深入研究或使用 Tarsier2,可參考以下資源:
- GitHub 倉庫:Tarsier2 官方開源專案
- 技術論文:Tarsier2 arXiv 技術論文
結論
Tarsier2 代表了當前視覺語言模型(LVLM)的最新技術突破,具備高品質視頻描述、視頻問答、事件定位、多語言支援等強大功能。在基準測試中超越 GPT-4o 和 Gemini-1.5-Pro,顯示出卓越的性能與實用性。
對於想要提升視頻內容理解、搜尋優化、影片標註或開發 AI 驅動的影音應用的企業與研究者來說,Tarsier2 提供了一個強大且開源的解決方案,未來潛力無限。
常見問題與答覆
1. Tarsier2 是什麼?
Tarsier2 是位元組跳動(ByteDance)推出的一款先進的大規模視覺語言模型(LVLM),專門用於理解和描述視頻內容。它可以生成高品質的視頻描述,支援視頻問答、事件定位和多語言解析,在多項基準測試中表現優異,甚至超越 GPT-4o 和 Gemini-1.5-Pro。
2. Tarsier2 的主要技術優勢是什麼?
Tarsier2 具備三大技術突破:
- 大規模預訓練數據——使用 4000 萬視頻-文本對資料,大幅提升模型的學習能力與準確性。
- 細粒度時間對齊技術——透過監督微調(SFT),確保生成的視頻描述與實際畫面對應,提升精準度。
- 直接偏好優化(DPO)訓練——透過模型自動生成的正負樣本對,提高文本自然度與可讀性,減少幻覺資訊。
3. Tarsier2 可以應用在哪些場景?
Tarsier2 適用於多種場景,包括:
- 視頻內容標註:可用於視頻平台、SEO 優化、內容檢索等應用。
- 智能視頻問答(VQA):適合影音推薦、教育和互動式 AI 助手。
- 事件定位與分析:在監控、體育分析、教育等領域可精確標記關鍵事件。
- 降低幻覺資訊:適合用於新聞摘要、知識庫建構、內容審核等需求。
成為AI學習平台訂閱者

NT$300 / 1個月

NT$900 / 3個月

NT$3,000 / 12個月


