
在 AI 領域,大語言模型(LLM)經常會產生未對齊(unaligned)或不符合人類價值觀的回應,因此如何提升模型的對齊性成為重要研究課題。Aligner,由北京大學(PKU)研究團隊開發,是一種全新的大語言模型(LLM)對齊技術,通過學習答案修正殘差,幫助 AI 生成更準確、安全且符合人類價值觀的回應。
不同於傳統的 強化學習從人類回饋(RLHF) 方法,Aligner 採用自回歸 seq2seq 模型,在問題-答案-修正後的答案(Q-A-C)資料集上訓練,不僅高效且靈活,還能作為隨插即用(plug-and-play)模組,直接應用於各種開源與 API 模型,如 GPT-3.5、GPT-4、Claude 2 等。
本文將深入解析 Aligner 的技術原理、應用場景與性能表現,幫助讀者理解這項 AI 模型對齊技術的革新突破。

🔍 Aligner 的核心技術解析
🎯 1. 修正殘差學習 提升模型對齊能力
Aligner 採用自回歸 seq2seq 模型,透過學習對齊答案與未對齊答案之間的差異(修正殘差),提升 LLM 回應的準確性與符合度。這一技術能夠:
✅ 精確修正 AI 回應 —— 讓模型輸出更符合語境與人類價值觀
✅ 提升 LLM 對話連貫性 —— 減少 AI 產生無意義、重複或不準確的回應
✅ 優化模型回應安全性 —— 避免 AI 生成有害、不當或偏見性的內容
💡 2. 無需 RLHF 直接優化大語言模型
Aligner 不依賴強化學習從人類回饋(RLHF),而是基於問題-答案-修正後的答案(Q-A-C)資料集進行訓練。這種方式:
✅ 避免 RLHF 訓練的高昂成本(RLHF 需要大量標註數據與計算資源)
✅ 更易於與現有 LLM 兼容,無需直接訪問模型參數
✅ 可在多種語言模型上運行,支援 GPT-3.5、GPT-4、Claude2、Llama2-70B 等
🔄 3. 隨插即用技術 提供靈活應用方案
Aligner 最大的優勢之一是可作為模組化技術直接應用於現有 LLM,不需要修改原始模型參數。例如:
✅ 開源模型(Llama2-70B、Mistral-7B)
✅ 閉源 API 模型(GPT-4、Claude 2)
這種靈活性讓 Aligner 成為當前 LLM 對齊領域中最具通用性的方法之一。
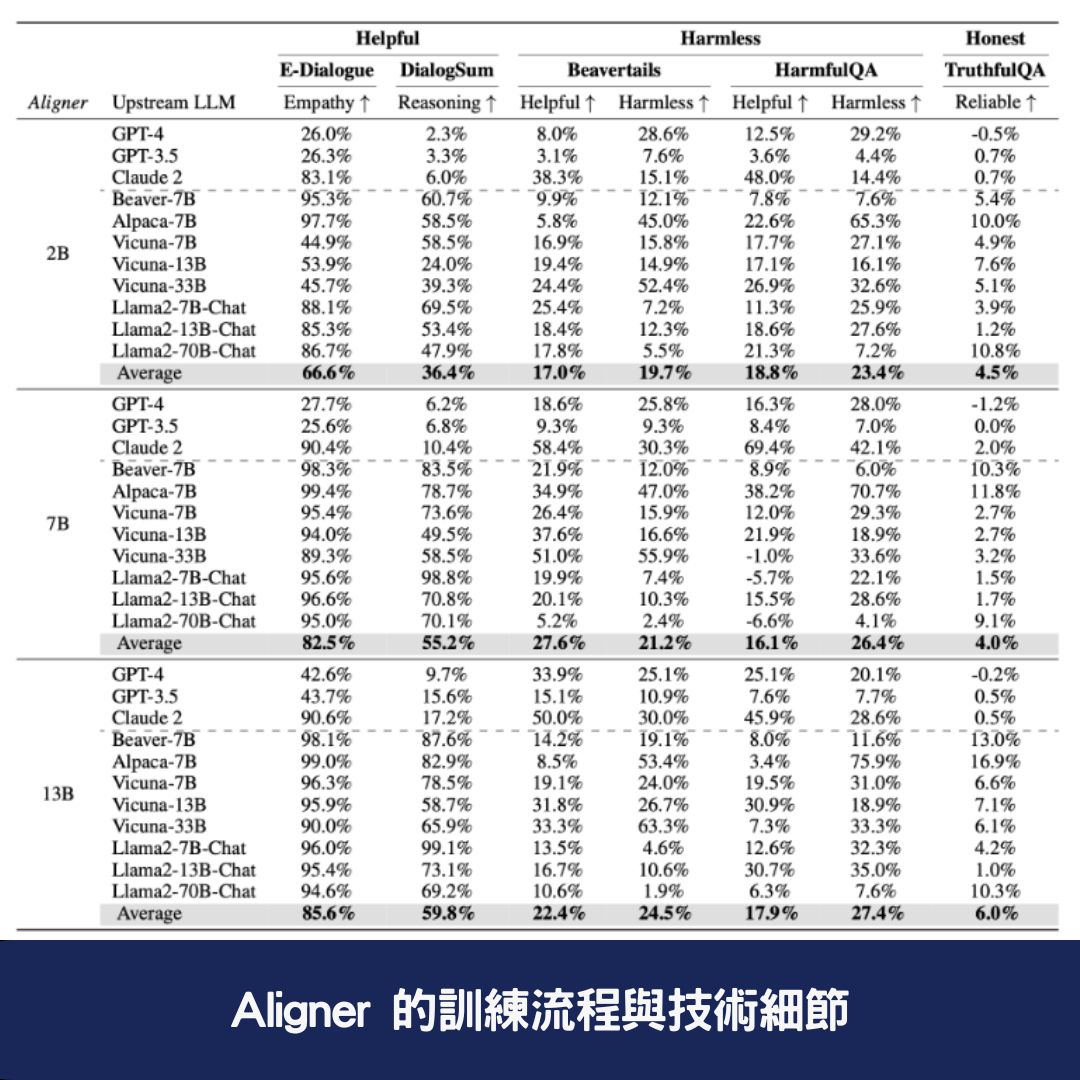
⚙️ Aligner 的訓練流程與技術細節
Aligner 的訓練過程主要分為三個階段:
📥 1. 資料收集(Data Collection)
🔹 從各種開放數據集中收集問題(Query)與原始答案(Answer)
🔹 讓 GPT-4、Llama2-70B-Chat 或人工標註者修正答案(Correction)
🔹 建立Q-A-C(問題-答案-修正後的答案)訓練資料集
🤖 2. 模型訓練(Model Training)
Aligner 透過 seq2seq 訓練方式,學習 原始答案與修正答案之間的差異(修正殘差),進一步提升 LLM 的語言對齊能力。
🔄 3. 訓練結果應用(Model Deployment)
Aligner 訓練完成後,可直接應用於 多種 LLMs,如 GPT-4、Llama2-70B、Claude2 等,實現即時修正與語言對齊優化。
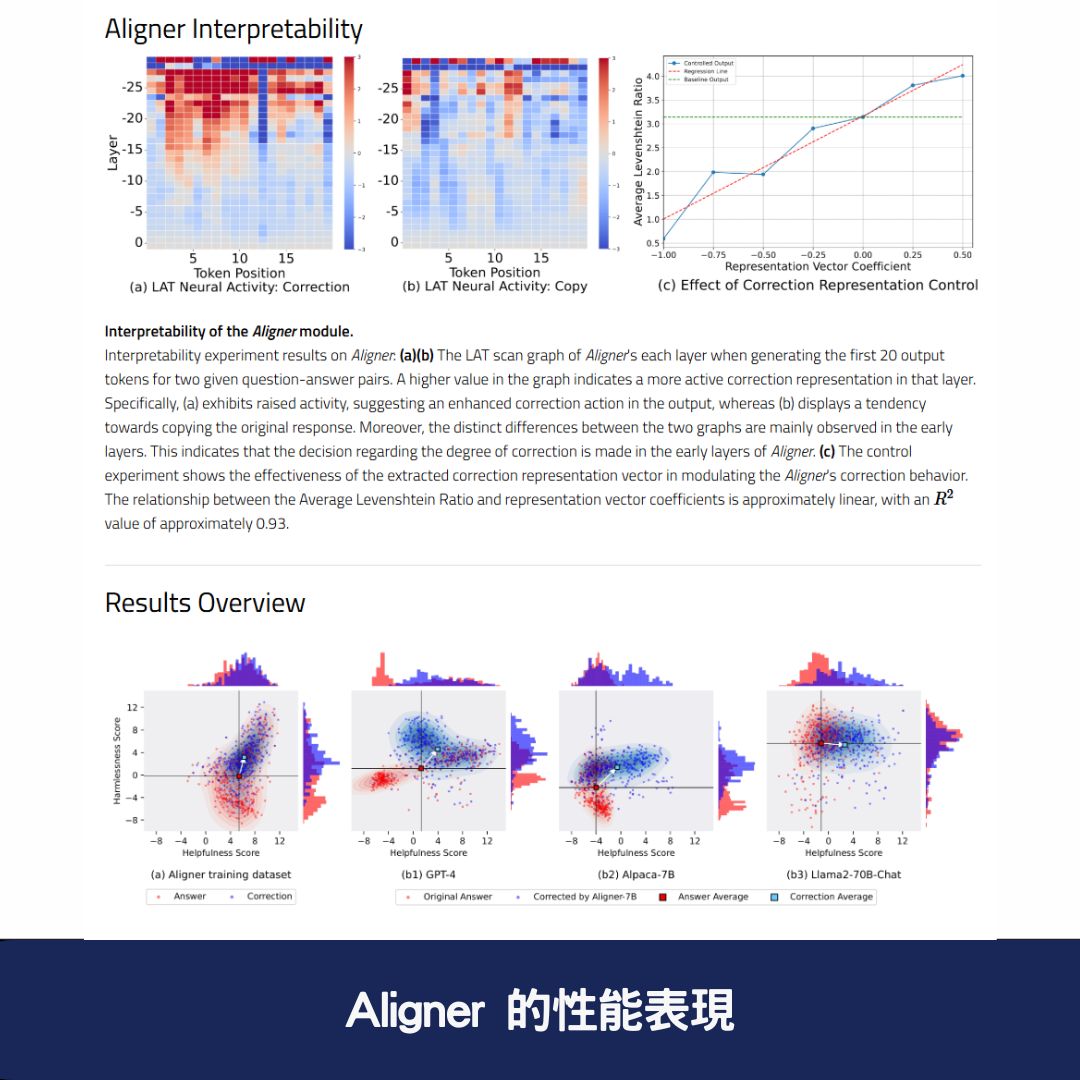
📊 Aligner 的性能表現
根據實驗數據,Aligner 顯著提升了多種語言模型的幫助性與安全性:
| Aligner 版本 | 適用模型 | 幫助性提升 | 安全性提升 |
|---|---|---|---|
| Aligner-7B | GPT-4 | +17.5% | +26.9% |
| Aligner-13B | Llama2-70B | +8.2% | +61.6% |
| Aligner-7B | 其他 11 種模型 | 顯著提升 | 顯著提升 |
這顯示 Aligner 能有效提升語言模型的回應品質與安全性,並且具備強大的泛化能力。
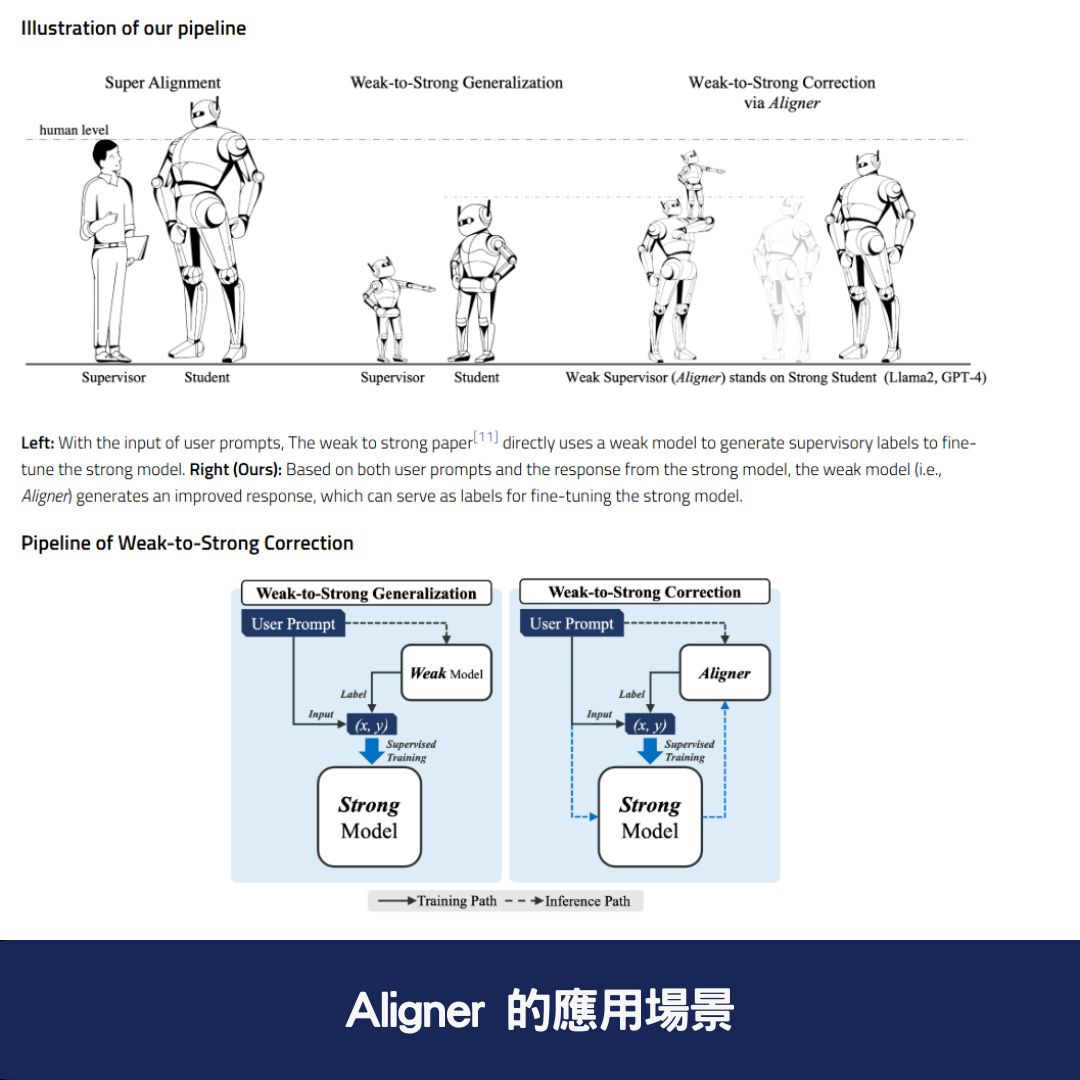
📌 Aligner 的應用場景
🗣 1. AI 多輪對話優化
在 AI 對話應用中,如 虛擬助理、客服機器人,Aligner 能提升對話的自然度與準確性,確保 AI 回應更符合語境需求。
🔍 2. 語言模型對齊與價值觀調整
Aligner 可根據不同應用需求,訓練 AI 模型符合特定價值觀,例如:
✅ 法律 AI 助理 —— 確保 AI 產出的法律建議符合專業標準
✅ 醫療 AI 系統 —— 確保 AI 回應符合醫學倫理與安全規範
🏢 3. 企業級 AI 應用強化
Aligner 可優化企業內部 AI 系統,確保 AI 在處理商業資訊、自動客服與決策建議時,提供更高質量的回應。
🎯 為何選擇 Aligner?
✅ 無需 RLHF 訓練,降低 LLM 調整成本
✅ 可適用於多種 LLM,如 GPT-4、Claude2、Llama2-70B
✅ 提升 AI 回應的準確性、安全性與符合度
✅ 提供即時語言對齊技術,適用於多輪對話與企業應用
🚀 想了解更多?立即訪問 Aligner 官方網站,體驗最新的 LLM 對齊技術!
文章閱讀後常見問題與答覆
1. Aligner 的主要功能是什麼?
Aligner 是 北京大學研究團隊 開發的一種 大語言模型(LLM)對齊技術,透過 學習對齊答案與未對齊答案之間的修正殘差,讓 AI 生成更準確、安全且符合人類價值觀的回應。其核心功能包括:
✅ 修正 AI 回應,確保語境適當並符合人類價值觀
✅ 無需 RLHF 訓練,降低語言模型優化的成本
✅ 可作為 Plug-and-Play 模組,適用於 GPT-4、Claude2、Llama2-70B 等多種 LLM
2. Aligner 如何提升 AI 的回應品質?
Aligner 透過 seq2seq 訓練方式,在 問題-答案-修正後的答案(Q-A-C)資料集 上學習 AI 的錯誤與最佳回應之間的差異,使 LLM:
📌 提升幫助性(例如回應更完整、語意更準確)
📌 提升安全性(避免 AI 產生有害、不當或偏見性的回應)
📌 確保語言模型對話連貫性,改善 AI 的上下文理解
3. Aligner 與傳統 RLHF(強化學習從人類回饋)技術有何不同?
Aligner 不依賴 RLHF,而是透過 修正殘差學習,讓 AI 直接學習正確答案與錯誤答案的差異。相較於 RLHF,Aligner 具有以下優勢:
✅ 訓練成本更低 —— 無需大量人工標註數據與高昂運算資源
✅ 適用於 API 模型 —— 可對齊 GPT-4、Claude 2 等無法訪問參數的模型
✅ 高效提升多種 LLM 的性能 —— 測試結果顯示,Aligner-7B 能提高 GPT-4 的幫助性 +17.5%,安全性 +26.9%
成為AI學習平台訂閱者

NT$300 / 1個月

NT$900 / 3個月

NT$3,000 / 12個月


