Baichuan-Omni-1.5 是 百川智能 推出的 全模態 AI 模型,支援 文本、圖像、音訊與視頻的全面理解,並具備 文本與音訊的雙模態生成能力。該模型在 視覺處理、語音技術、多模態流式交互 等方面表現優異,尤其在 醫療領域、智慧交互、教育輔助 等應用場景中展現出色實力。
本篇文章將深入解析 Baichuan-Omni-1.5 的核心功能、技術優勢與應用範圍,幫助讀者了解這款強大的 AI 模型。
Baichuan-Omni-1.5 的核心功能

Baichuan-Omni-1.5 在多模態 AI 技術方面具備強大能力,並在多個領域超越傳統 AI 模型,特別是在 視頻理解、語音交互、醫療分析 方面表現突出。
1. 全模態理解與生成
- 支援文本、圖像、音訊、視頻的全模態理解,可實現跨模態內容解析與轉換。
- 具備文本與音訊的雙模態生成能力,能根據語音輸入生成文本,或根據文本生成高品質語音。
2. 多模態交互技術
- 支援即時音視頻互動,提供流暢的智慧對話體驗。
- 能夠根據使用者提供的圖片、音訊或文本內容進行跨模態解析與互動。
3. 高效音訊處理技術
- 採用端到端音訊處理方案,支援 多語言對話、語音辨識(ASR)、文本轉語音(TTS)。
- 音訊 Tokenizer 由 Whisper 增量訓練,具備更高精度的語義抽取與語音合成能力。
4. 強大的視頻理解能力
- 模型經過視頻理解優化,能夠準確分析視頻內容,並生成對應的文本描述。
- 在視覺處理測試中,表現優於 GPT-4o-mini,具備更強的影像識別與內容解析能力。
5. 多模態推理與遷移學習
- 擁有強大的跨模態遷移能力,能靈活應對複雜場景,實現不同模態間的精準信息傳遞。
- 在醫療影像、語音分析等領域表現優異,能夠進行更深層次的資料理解與推理。
Baichuan-Omni-1.5 的技術原理
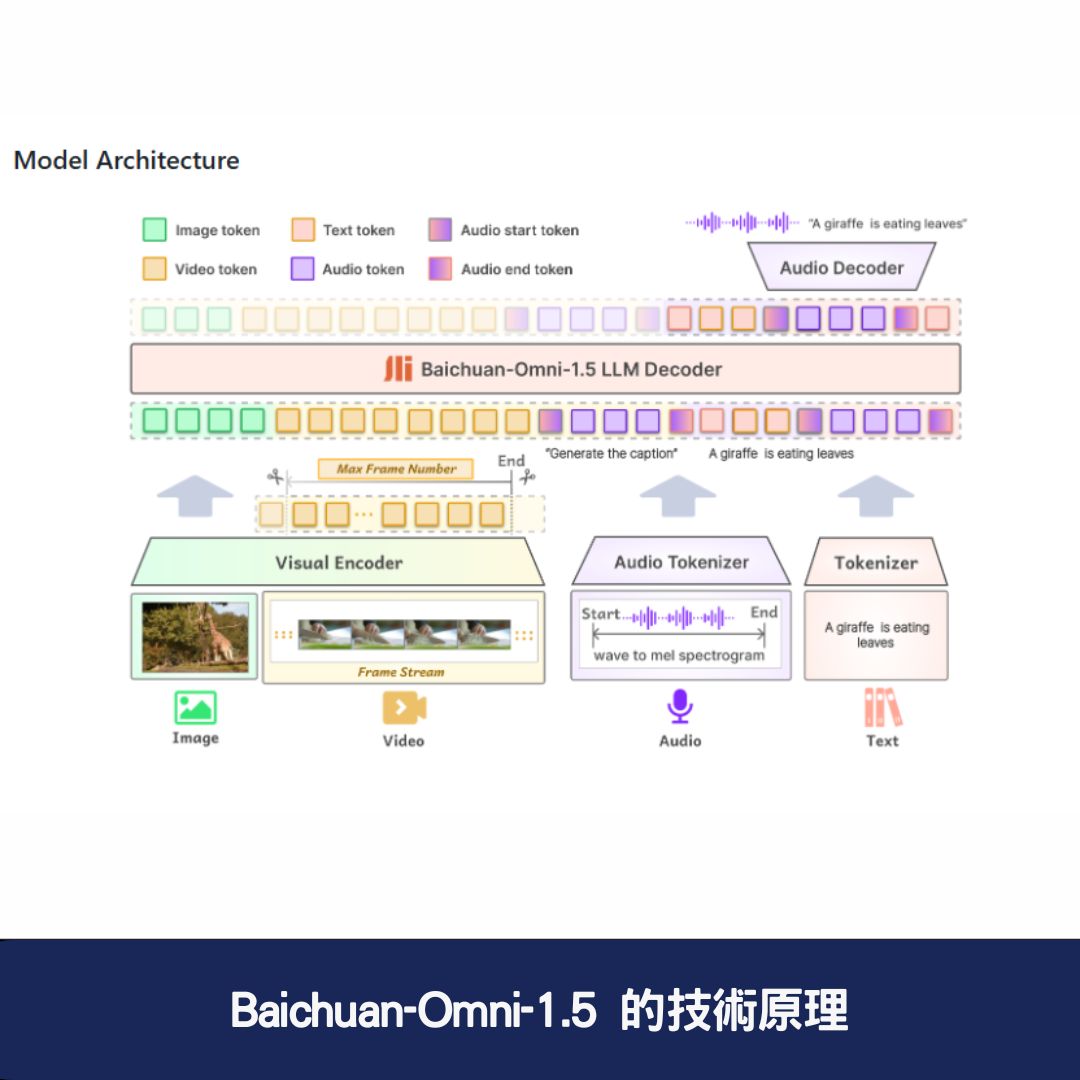
1. 多模態架構設計
Baichuan-Omni-1.5 採用 多模態架構,支援 文本、圖像、音訊、視頻的綜合處理。
- 透過視覺編碼器(Encoder)處理圖像與視頻資料。
- 音訊編碼器負責音訊處理,並與大型語言模型(LLM)整合。
- 採用文本-音訊交錯輸出的方式,提升多模態內容的生成能力。
2. 多階段訓練與優化
- 圖像-語言、視頻-語言、音訊-語言對齊預訓練,確保不同模態的高效融合。
- 監督微調(SFT) 阶段使用 1700 萬條全模態資料 進行訓練,大幅提升模型的準確性與適應能力。
3. 超大數據構造與優化
- 模型訓練數據包含 3.4 億條高品質圖片/視頻-文本對應資料。
- 累積近 100 萬小時音訊數據,確保 AI 在語音處理方面的卓越表現。
4. 注意力機制與資源優化
- 使用動態注意力機制,根據不同輸入模態的權重進行最佳化。
- 實現更高效的計算資源分配,提高 AI 模型的處理能力。
Baichuan-Omni-1.5 的應用場景

1. 智慧客服與交互優化
- 能處理文字、語音、圖片等多模態資訊,提高客服精準度與效率。
- 使用者可發送產品圖片、語音提問,AI 立即進行解析並提供最佳解答。
2. 教育輔助與學習提升
- 可作為智慧學習助手,解讀教材、解析圖表、進行語音講解。
- 根據學生的學習風格提供個性化教學,激發學習興趣。
3. 醫療智慧診斷與影像分析
- 支援醫學影像解析,能理解檢查報告與語音敘述,輔助醫生診斷。
- 結合多模態輸入,提供更準確的醫學建議與治療方案。
4. 創意內容生成與設計支援
- 能根據文本描述生成相關圖片、動畫或音訊,助力創意工作。
- 在廣告、影視、數位設計等領域,提供 AI 賦能的創新解決方案。
5. 多模態內容生成與語音應用
- 可根據視頻內容生成高品質的語音解說與字幕。
- 適用於多語言即時翻譯、語音助理與智慧導航等場景。
Baichuan-Omni-1.5 是多模態 AI 領域的領先技術

Baichuan-Omni-1.5 以其 全模態理解、跨模態推理、強大音視頻處理能力,在 智慧交互、教育、醫療、創意產業 等領域帶來重大突破。
如果你希望 提升客服效率、優化學習體驗、增強醫療診斷、激發創意靈感,Baichuan-Omni-1.5 無疑是最佳選擇。
🔗 Baichuan-Omni-1.5 官方資源:
常見問題與答覆(FAQ)
1. Baichuan-Omni-1.5 與傳統 AI 模型相比,有哪些優勢?
Baichuan-Omni-1.5 是一款 全模態 AI 模型,能夠同時處理 文本、圖像、音訊與視頻,並具備 文本與音訊的雙模態生成能力。在 視頻理解、語音處理、多模態推理 等領域超越 GPT-4o-mini,尤其在醫療應用、智慧客服和教育輔助方面展現出色表現。
2. Baichuan-Omni-1.5 如何提升多模態交互能力?
Baichuan-Omni-1.5 採用 多模態架構與動態注意力機制,能夠根據不同輸入模態(如圖片、語音、文本)進行智能分析與內容轉換。透過 端到端音訊處理技術、視覺編碼器與大型語言模型整合,可支援 即時語音交互、圖像識別與視頻內容理解,大幅提升用戶體驗。
3. Baichuan-Omni-1.5 在醫療與教育領域有哪些應用?
在 醫療領域,Baichuan-Omni-1.5 可解析 醫學影像、病歷文本與語音敘述,輔助醫生診斷並提供治療建議。在 教育領域,它能理解 教材文本、圖表、語音講解,並根據學生的學習需求提供個性化輔助,如智能答疑與知識點拆解,提升學習效率。
成為AI學習平台訂閱者

NT$300 / 1個月

NT$900 / 3個月

NT$3,000 / 12個月