DeepSeek R1-Zero 是 DeepSeek 團隊 開發的 完全依賴純強化學習(RL)訓練 的推理模型,它 未使用任何監督微調(SFT)資料,卻在 數學、代碼和自然語言推理 任務中展現出 卓越的推理能力。尤其是在 AIME 2024 數學競賽 中,其 Pass@1 分數 從 15.6% 提升至 71.0%,接近 OpenAI-o1-0912 的水準。
本文將深入探討 DeepSeek R1-Zero 的主要功能、技術原理、應用場景 和 技術優勢,幫助您了解這款 革命性推理模型 的潛力與應用價值。
DeepSeek R1-Zero 的主要功能

DeepSeek R1-Zero 的成功來自於其 純強化學習訓練、自我進化能力 和 卓越的推理性能,以下是其五大核心功能:
1. 強大的推理能力
- 卓越的推理性能: DeepSeek R1-Zero 通過 大規模強化學習,在 數學、代碼和自然語言推理 任務中表現出色,尤其在 AIME 2024 數學競賽中,其 Pass@1 分數 從 15.6% 提升至 71.0%,接近 OpenAI-o1-0912 的水準。
- 複雜推理任務表現優異: 在 多步推理、長上下文分析和數學推導 中,展現出 高效的邏輯推理和決策能力。
2. 純強化學習驅動
- 無監督微調: DeepSeek R1-Zero 是 首個完全通過強化學習訓練的推理模型,未使用任何監督微調資料(SFT),證明了 無需標注資料也能實現高效的推理能力。
- 從零開始自主學習: 模型通過 試錯學習複雜的推理策略,如 數學推導、代碼優化、語言推理 等,顯示出 自主學習和決策的能力。
3. 自我進化與湧現行為
- 自我進化能力: 在訓練過程中,DeepSeek R1-Zero 展現出 自我進化能力,如 反思、重新評估推理步驟 等複雜行為,這些行為 並非預設,而是通過強化學習自然湧現。
- 自適應策略優化: 模型能夠 自動調整推理策略和計算步驟,達到 最優化的解題效果。
4. 高效的蒸餾技術
- 多種模型版本: 基於 DeepSeek R1-Zero 蒸餾出的多個小模型(如 7B、32B、70B),在推理任務中 性能接近甚至超過一些閉源模型,並且 效能更高、資源消耗更低。
- 開源與社區支持: DeepSeek R1-Zero 的模型權重已開源,遵循 MIT License,支援社群貢獻與二次開發。
5. 多語言支援與優化
- 多語言推理與翻譯: DeepSeek R1-Zero 在 多語言推理和翻譯任務中表現出色,支援 中、英、日、法等多語言推理和語言轉換。
- 語言一致性獎勵: 為了解決 語言混雜問題,引入 語言一致性獎勵機制,提升 多語言輸出的一致性與準確性。
DeepSeek R1-Zero 的技術原理
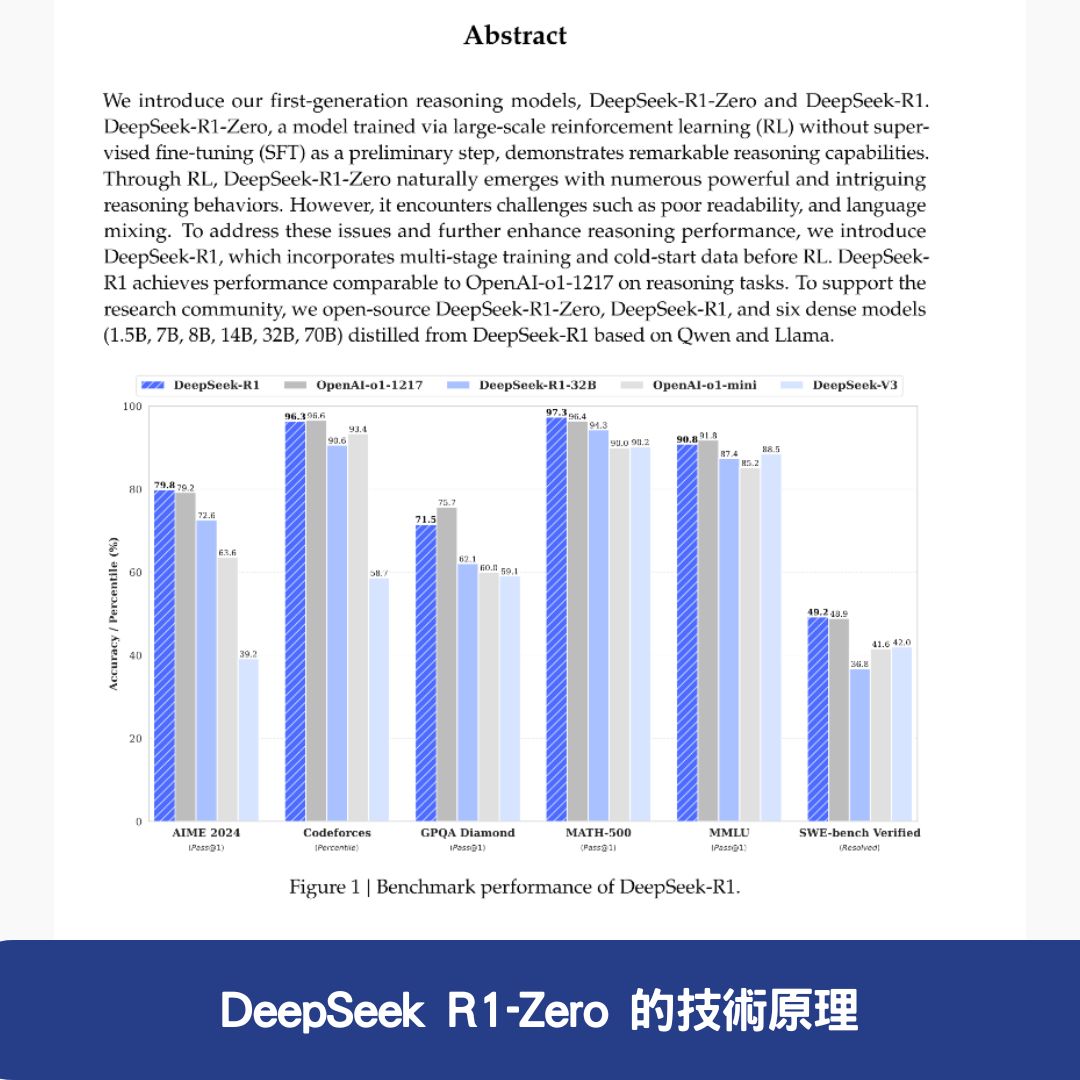
DeepSeek R1-Zero 的成功背後,依賴於其創新的 純強化學習訓練、GRPO 演算法 和 長上下文支持,以下是其主要技術原理:
1. 純強化學習訓練
- 跳過監督微調步驟: DeepSeek R1-Zero 從基礎模型(如 DeepSeek-V3-Base)出發,直接通過大規模強化學習 提升推理能力,跳過了傳統的監督微調步驟。
- 試錯學習推理策略: 模型 在沒有標注資料的情況下,通過 試錯學習(Trial and Error),自主探索並學習複雜的推理策略。
2. GRPO 演算法(Group Relative Policy Optimization)
- 組內歸一化獎勵信號: DeepSeek R1-Zero 採用了 GRPO 演算法,通過組內歸一化獎勵信號 優化策略,避免了傳統 PPO(Proximal Policy Optimization)中需要額外訓練價值模型的高成本。
- 優勢函數生成: GRPO 透過 組內獎勵的均值和標準差,生成 優勢函數,優化策略並提升推理效率。
3. 自我進化與湧現行為
- 自然湧現的自我反思與進化: 在訓練過程中,DeepSeek R1-Zero 展現出 自我反思、重新評估推理步驟 等 複雜行為,這些 湧現行為並非預設,而是 通過強化學習自然而然地產生。
- 自適應策略調整: 模型能夠 自動調整推理策略,使推理步驟更加 高效且準確。
DeepSeek R1-Zero 的應用場景
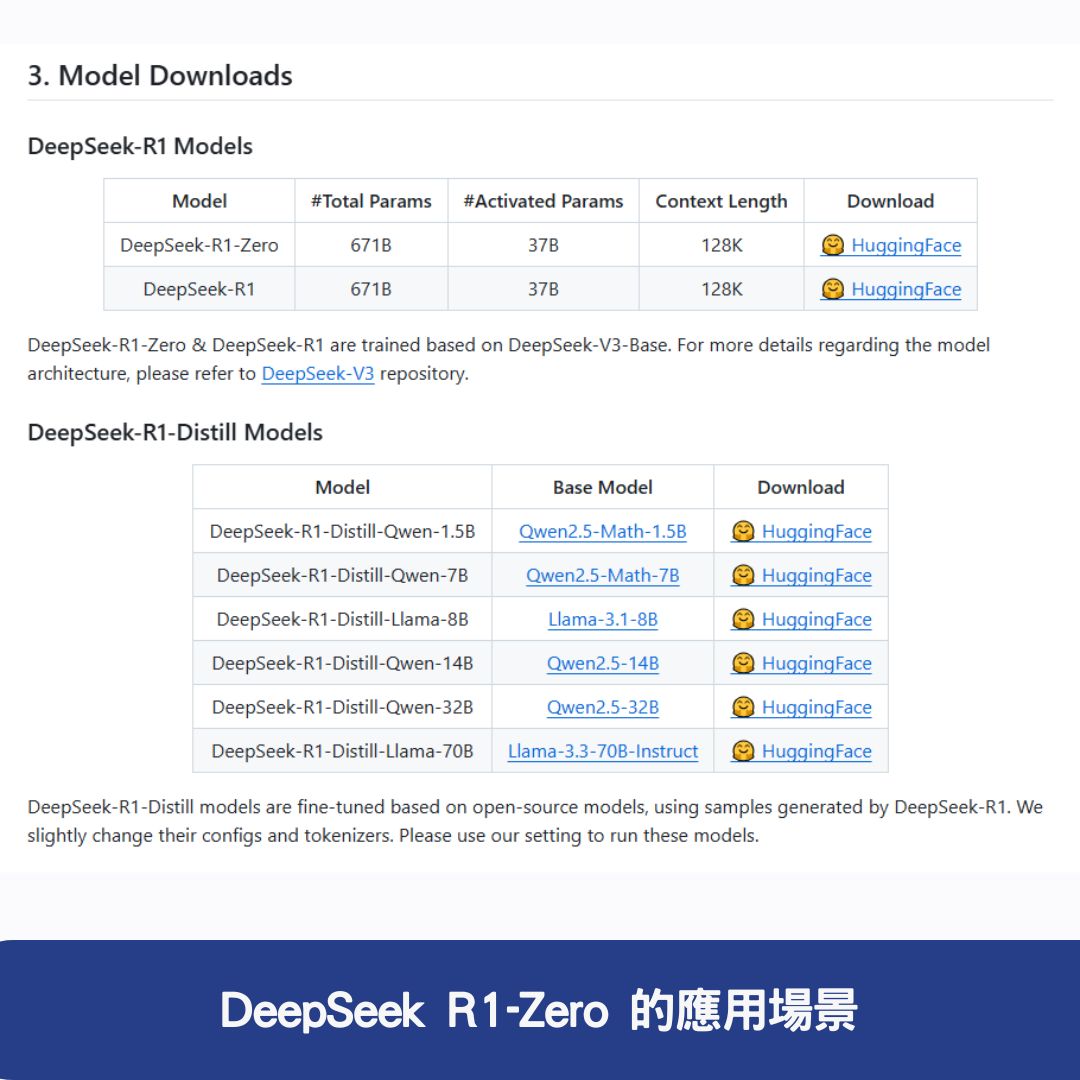
DeepSeek R1-Zero 的 高效推理能力與多語言支援,使其在多種應用場景中表現出色,包括:
1. 教育與智慧輔導
- 個性化學習計畫: DeepSeek R1-Zero 可用於 個性化學習計畫的制定 和 智慧輔導系統,根據 學生的學習進度與興趣,提供 針對性的練習和回饋。
2. 醫療健康與輔助診斷
- 輔助診斷與早期篩查: DeepSeek R1-Zero 可 分析大量醫學資料,例如 醫學影像和電子病歷,協助 癌症等疾病的早期篩查與輔助診斷。
3. 自動駕駛與路徑規劃
- 快速決策與路徑優化: DeepSeek R1-Zero 在 自動駕駛領域 能根據 交通狀況與突發情況 做出 快速決策與路徑優化,提升 行車安全性。
4. 代碼生成與優化
- 程式設計競賽與代碼優化: 在 Codeforces 等程式設計競賽 中,DeepSeek R1-Zero 生成高品質的代碼解決方案,並 自動優化和重構。
結論
DeepSeek R1-Zero 是一款 完全強化學習推理模型,以其 自我進化、自主學習、高效推理 的特性,重新定義了 推理模型的邊界。
- HuggingFace模型庫:https://huggingface.co/deepseek-ai/DeepSeek-R1-Zero
常見問題與答覆
Q1:DeepSeek R1-Zero 是什麼?
A1:DeepSeek R1-Zero 是 DeepSeek 團隊 開發的 完全依賴純強化學習(RL)訓練 的推理模型,未使用任何監督微調(SFT)資料。它在 數學、代碼和自然語言推理 任務中表現出色,尤其在 AIME 2024 數學競賽 中,其 Pass@1 分數從 15.6% 提升至 71.0%,接近 OpenAI-o1-0912 的水準。
Q2:DeepSeek R1-Zero 的主要功能有哪些?
A2:DeepSeek R1-Zero 的主要功能包括:
- 強大的推理能力: 在 數學、代碼和自然語言推理 任務中表現出色,具備 多步推理和長上下文分析 能力。
- 純強化學習驅動: 是 首個完全通過強化學習訓練的推理模型,未使用 任何監督微調資料。
- 自我進化與湧現行為: 展現出 自我反思、重新評估推理步驟 的 複雜行為,並 自主調整推理策略。
Q3:DeepSeek R1-Zero 的應用場景有哪些?
A3:DeepSeek R1-Zero 可廣泛應用於:
- 教育與智慧輔導: 用於 個性化學習計畫 和 智慧輔導系統,提供 針對性的練習和回饋。
- 醫療健康: 用於 輔助診斷和早期篩查,分析 醫學影像和電子病歷。
- 自動駕駛: 在 自動駕駛領域,能根據 交通狀況和突發情況 做出 快速決策與路徑優化。
- 代碼生成與優化: 在 程式設計競賽和代碼優化 任務中表現出色,能 生成高品質的代碼解決方案。
成為AI學習平台訂閱者

NT$300 / 1個月

NT$900 / 3個月

NT$3,000 / 12個月