隨著 大語言模型(LLMs) 在各領域應用的增加,如何評估其 準確性、可靠性與業務適配度,成為企業和研究機構的重要課題。LalaEval,由 香港中文大學(CUHK)與貨拉拉(Lalamove)數據科學團隊 共同研發,是一款 專為特定領域 LLM 設計的人類評估框架,已成功應用於 物流行業,幫助企業 優化 AI 模型在實際場景中的表現。
LalaEval 的核心特色在於 建立標準化測試機制,並透過爭議度與評分波動分析,自動糾正人工評估錯誤,確保評估結果的 客觀性與高品質。
本文將詳細解析 LalaEval 的技術原理、應用場景與企業優勢,幫助讀者理解這套 高效 AI 評估框架如何提升 LLM 在產業中的適應性與準確度。

🔍 LalaEval 的核心技術與評估流程
🎯 1. 建立特定領域的 LLM 評測框架
LalaEval 提供完整的 端到端(end-to-end)評估協定,涵蓋 領域範圍界定、能力指標構建、評測集生成、評測標準制定與結果分析。這種方法確保 LLM 在特定產業應用中的可測性與可調適性,如:
✅ 物流 AI 模型測試 —— 測試 AI 在同城貨運、訂單管理中的表現
✅ 企業內部 LLM 評估 —— 幫助企業優化內部 AI 模型的問答準確度
✅ AI 司機邀約場景測試 —— 透過模擬對話,測試 AI 在自動化邀約任務中的準確度
📊 2. 定義 LLM 的能力指標
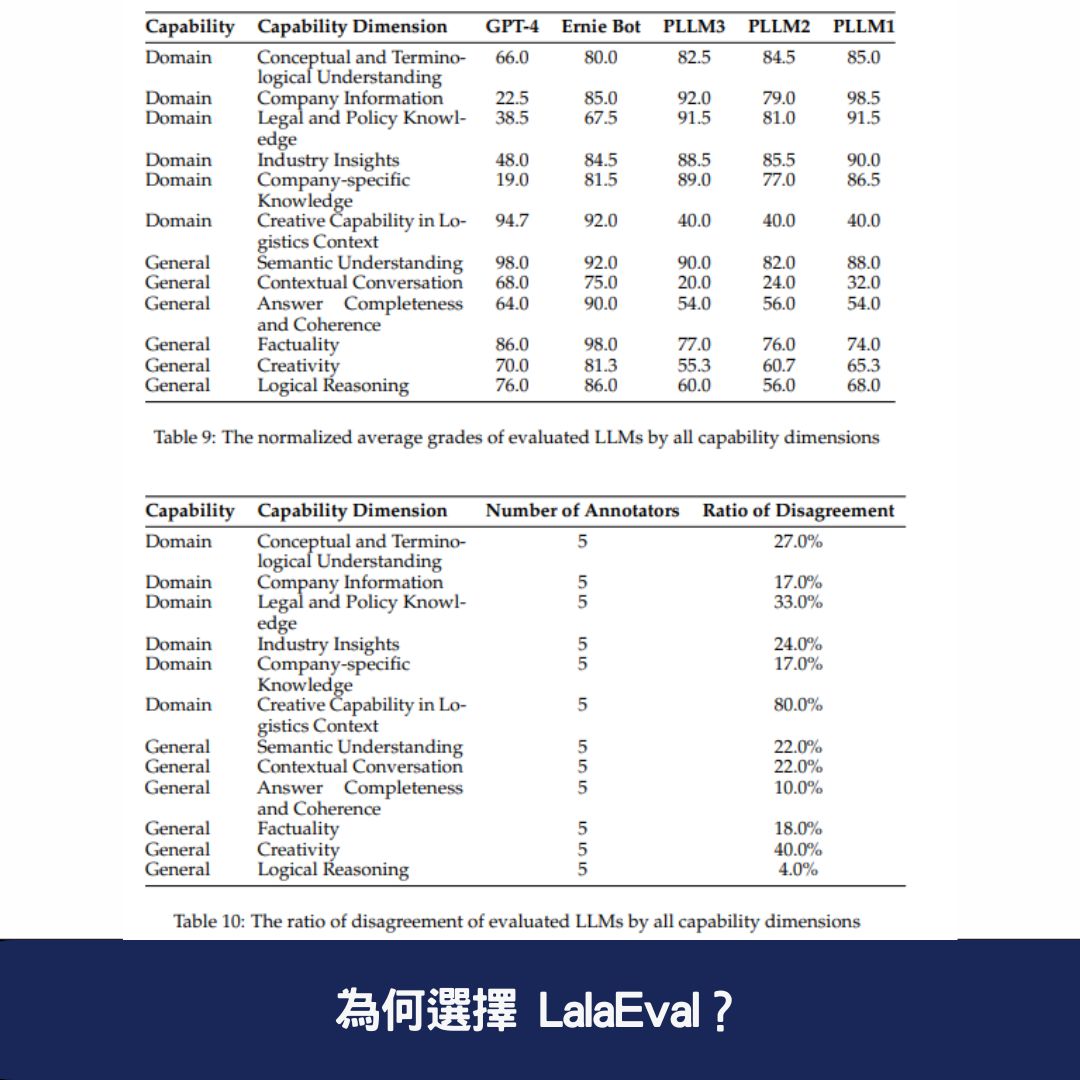
LalaEval 針對 LLM 的表現構建多維度能力評估標準,包含:
🔹 通用能力 —— 如 語義理解、上下文對話、事實準確性
🔹 領域專業能力 —— 如 行業術語理解、法規與政策應用
🔹 互動適配性 —— AI 在特定場景中的反應與應對能力
這些標準確保 LLM 能在不同產業環境中適應並產生高質量回應。
📥 3. 生成標準化評測集
LalaEval 透過人工標註與自動化方式 建立高品質的測試數據集,包括:
✅ 從經過驗證的資訊來源收集標準測試題
✅ 建立問答數據集(QA Pairs),涵蓋真實業務場景
✅ 確保測試條件一致,避免外部因素影響評估結果
🏷 4. 設計結構化評測標準
為確保 評估的一致性與科學性,LalaEval 為人類評估者提供標準化評分方案,確保 AI 回應的評價能夠被量化與比較,減少 人工主觀誤差。
🔄 5. 評估結果的自動分析與糾錯
LalaEval 採用 爭議度與評分波動分析技術,透過以下指標自動糾正評估錯誤:
📌 評分爭議度分析 —— 比較不同評審者的評分一致性
📌 題目爭議度檢測 —— 檢查測試題目是否導致評分偏差
📌 評分波動性監測 —— 避免評估過程因評審者認知差異產生誤判
這些技術確保 AI 評估能夠 排除人為偏差,提高準確性。
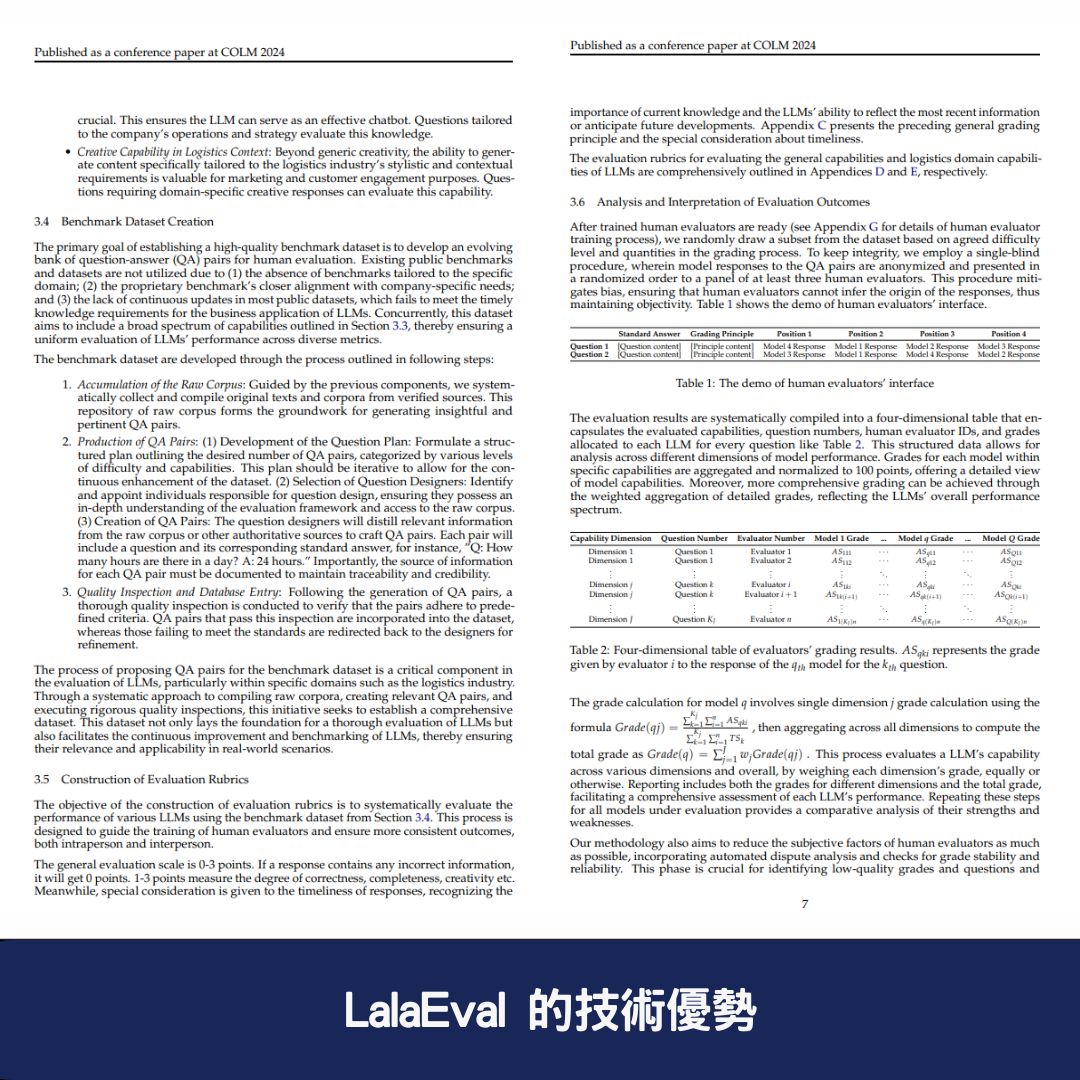
⚙️ LalaEval 的技術優勢
🔬 1. 採用單盲測試 保持評估客觀性
LalaEval 在評估過程中匿名化 AI 回應,並以隨機順序呈現給至少三名人類評估者,避免主觀偏見影響結果,確保評測數據的 公平性與公正性。
🔍 2. 模組化與動態交互部署
LalaEval 的評估系統 強調模組化架構,可根據不同企業需求靈活調整,適應多種業務場景,如:
✅ 物流與運輸業 AI 測試
✅ 客服自動化對話評估
✅ 企業內部 AI 助手測試與優化
這種彈性架構讓 LalaEval 具備跨產業應用的潛力。
📊 3. 自動化評分糾錯機制
透過 AI 數據分析,LalaEval 能自動偵測評估錯誤,確保 低品質問答對的二次識別與糾正,提升評估結果的 一致性與可信度。

📌 LalaEval 的應用場景
🏢 1. 物流產業 AI 模型評估
貨運與物流業者可透過 LalaEval 來:
✅ 評估 LLM 在運輸、訂單管理、貨運規劃上的表現
✅ 確保 AI 能夠精確理解貨物配送的時效性與政策
✅ 優化客服機器人的自動回應,提高準確性與客戶滿意度
🤖 2. AI 自動邀約場景測試
在 司機邀約系統 中,LalaEval 可測試 AI 是否能夠:
✅ 有效引導司機完成接單流程
✅ 提供準確的時間與貨物資訊
✅ 避免 AI 回應含糊不清、影響溝通效率
📊 3. 企業內部 LLM 模型的優化與測試
LalaEval 可幫助企業:
✅ 量化 AI 助手的回應準確性,確保對內部數據的理解度
✅ 減少 AI 對話中的誤導性回應,提升企業內部溝通品質
✅ 提供標準化測試,確保 LLM 符合企業業務需求
🎯 為何選擇 LalaEval?
✅ 針對特定產業的 LLM 評估框架,確保 AI 回應符合業務需求
✅ 建立標準化測試數據集,確保評估過程科學化
✅ 透過單盲測試與自動評分糾錯,確保結果客觀可靠
✅ 可擴展至跨產業應用,靈活適應企業需求
🚀 想了解更多?立即訪問 LalaEval 技術論文,探索 AI 評測新標準!
文章閱讀後常見問題與答覆
1. LalaEval 是什麼?與其他 LLM 評測工具有何不同?
LalaEval 由 香港中文大學(CUHK)與貨拉拉數據科學團隊 共同開發,是一款 針對特定領域 LLM(大語言模型)設計的人類評估框架。與傳統 LLM 評測工具相比,LalaEval 具備以下優勢:
✅ 端到端評估流程 —— 涵蓋從領域規範、評測集建立到結果分析的完整測試機制
✅ 單盲測試 —— 確保 AI 回應的評分過程公平且無偏見
✅ 自動化爭議度分析 —— 透過統計方法糾正人工評估錯誤,提高結果可靠性
2. LalaEval 如何提升 LLM 在物流行業的應用?
LalaEval 已成功應用於物流產業,特別是在 同城貨運與 AI 司機邀約場景,幫助企業優化 AI 模型的準確性與業務適應性:
📌 評估 LLM 在貨運調度、訂單處理與客戶對話的表現
📌 確保 AI 回應符合物流政策與業務規範
📌 減少 AI 回應的不確定性,提高自動邀約與客服機器人的準確度
3. LalaEval 是否可應用於其他產業?
是的!LalaEval 採用 模組化與動態交互架構,可靈活調整評測流程,適用於不同產業,如:
✅ 金融與法務 AI 評測 —— 測試 AI 在金融法規與合規審查的表現
✅ 醫療 AI 測試 —— 確保 AI 回應符合醫學標準與診斷準確性
✅ 企業內部 AI 助手測試 —— 優化 AI 在內部知識管理與客戶支持的應用
成為AI學習平台訂閱者

NT$300 / 1個月

NT$900 / 3個月

NT$3,000 / 12個月