MILS(Multimodal Iterative LLM Solver)是由 Meta AI 推出的 無需額外訓練 的 多模態 AI 解決方案。它能夠透過 多步推理(Iterative Reasoning),讓大型語言模型(LLM)處理多種模態的資訊,如圖像、音訊、視頻等,並生成高品質的內容描述。
MILS 不需要額外標訓數據,就能讓 LLM 獲得強大的 跨模態處理能力,這在 AI 應用領域具有重要的突破。它能夠應用於 圖像、影片、音訊的描述生成,並且可用於 風格轉換、文本到圖像(T2I)優化、多模態檢索 等多種場景,對 媒體生成、智慧推薦系統、內容理解等領域 具有革命性的影響。

MILS 的核心功能
MILS 的強大之處在於它能夠處理各種多模態任務,並且不需要對 LLM 進行額外訓練。它的核心功能主要包括:
1. 多模態理解任務
MILS 透過 LLM 生成 文本描述 來理解不同類型的資料,例如:
- 圖像描述生成:輸入一張圖像,MILS 會自動生成詳細的文字描述,適用於社交媒體、影像標註等場景。
- 視頻描述生成:分析影片內容,生成摘要,應用於影片推薦、內容分析等領域。
- 音訊描述生成:透過分析聲音內容,產生描述性文字,例如用於字幕生成或語音助手。
- 跨模態推理:MILS 能夠將 圖像、音訊、視頻等不同模態的資訊轉換為文本,進行跨模態的推理與組合。
2. 多模態生成任務
除了理解多模態內容,MILS 也可以用來生成新的多模態內容,包括:
- 高品質圖像生成(T2I):MILS 透過優化文本提示詞(Prompt Engineering),讓 文本到圖像模型 產生更符合需求的圖片。
- 風格遷移:讓一張圖像的風格應用到另一張圖上,類似 AI 繪畫的風格轉換技術。
- 跨模態生成:將 音訊轉換成圖像、結合聲音與影像產生新的內容,適用於創意設計、數位藝術等領域。
3. 多步推理與反覆優化
MILS 採用 多步推理(Iterative Reasoning),能夠透過反覆迭代,讓 AI 不斷優化輸出結果:
- 初始輸出:LLM 根據提示詞生成多個候選結果。
- 評分與回饋:每個候選結果都會被評估(透過 AI 進行自動評分)。
- 最佳化輸出:MILS 會根據評分結果調整輸入,然後重新生成新的候選方案,直到找到最優解。
這種 反覆運算的方式,讓 AI 不需要額外訓練,就能透過 內部推理能力 來達到優化效果。
4. 無梯度優化技術
MILS 的另一個優勢是 無梯度優化(Gradient-Free Optimization),這意味著:
- 它不需要使用傳統 AI 訓練方式中的 反向傳播(Backpropagation),也就是 無需重新訓練 LLM。
- 透過 AI 自動評分與回饋機制,可以逐步提升模型的輸出結果。
這使得 MILS 能夠與各種現有的 LLM 兼容,並且可 直接部署在不同的應用場景,大幅提升 AI 在多模態領域的應用靈活度。
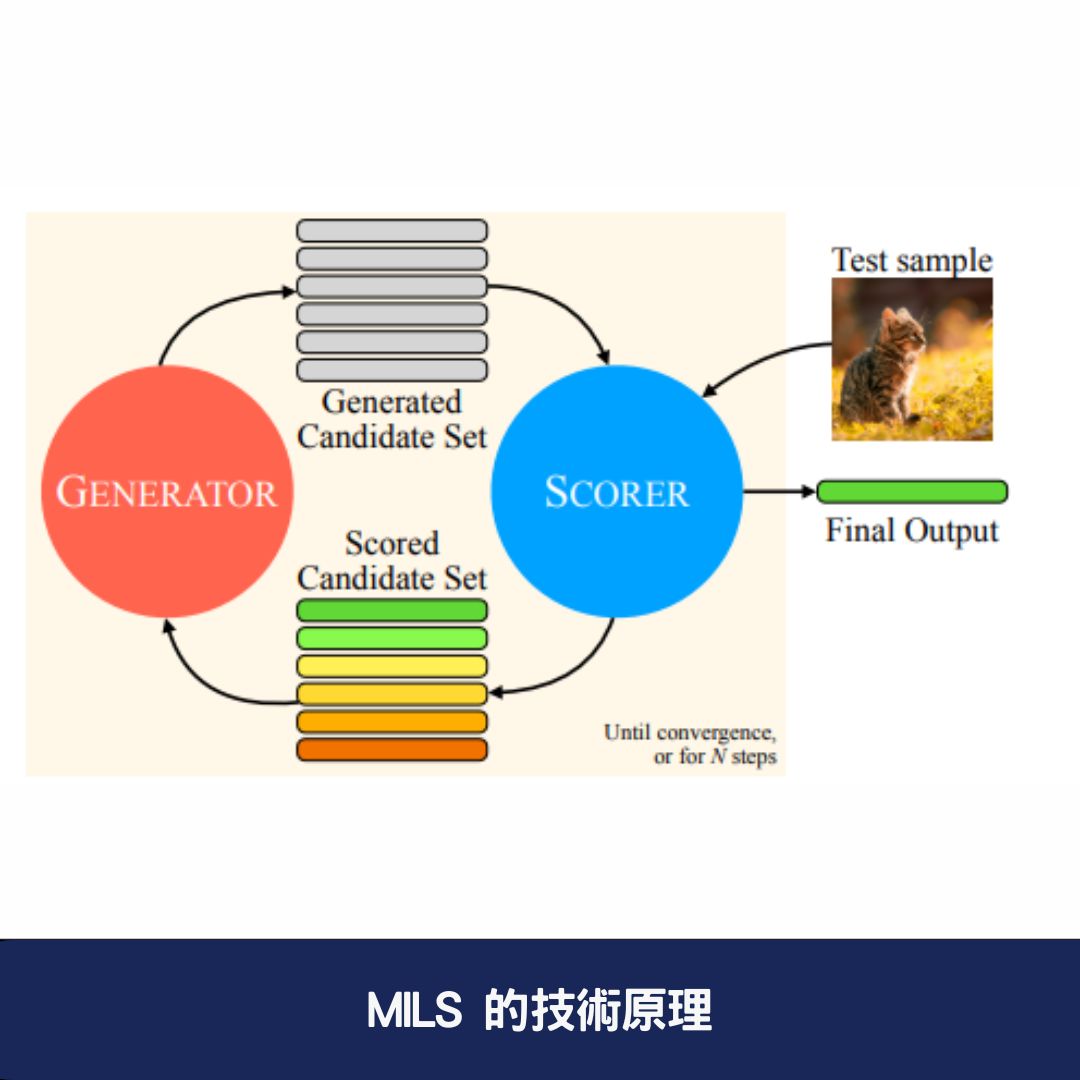
MILS 的技術原理
MILS 主要透過兩個核心組件來實現其強大的推理與生成能力:
1. 生成器(Generator)
- 功能:負責為特定任務生成候選輸出,接收 任務描述 和 評分回饋,並根據這些資訊產生新的候選方案。
- 應用:輸出不僅限於文本,還可以 引導其他 AI 模型 生成圖像、影片、音訊等多模態內容。
2. 評分器(Scorer)
- 功能:對 生成器的輸出 進行評分,確保最終結果與原始需求相符。
- 實現方式:
- 低階影像處理函數(例如比較圖像紋理、色彩分佈等)。
- 機器學習模型(如 CLIP),利用 AI 模型計算 圖像與文字的相似性,提升評分準確度。
這兩個組件相互配合,使 MILS 能夠在無需訓練的情況下 持續優化 AI 的輸出結果。

MILS 的應用場景
MILS 具備強大的 多模態處理能力,適用於許多 AI 相關領域,包括:
1. 社交媒體內容生成
- 自動生成圖像標題,讓社交媒體貼文更具吸引力。
- 透過 AI 改善圖像與文字的搭配度,提升用戶互動率。
2. 多模態檢索與智慧推薦
- 根據圖像、影片或音訊特徵,進行內容相似性檢索,應用於 AI 內容推薦、智能搜索。
3. 視覺問答與內容理解
- MILS 能夠 結合圖像和文本資訊,在 AI 助手、智慧客服 等場景中提供更準確的回答。
4. AI 輔助設計與內容創作
- 幫助創作者提升 文本到圖像生成(T2I)的品質,優化 AI 繪圖效果。
- 提供 風格轉換功能,實現跨媒體內容創作。
5. 多模態 RAG(Retrieval-Augmented Generation)
- 結合多模態檢索系統,讓 AI 在生成內容時考慮圖像、音訊、視頻等多種資訊,增強語言模型的生成能力。

如何開始使用 MILS?
MILS 已經開源,任何人都可以 直接試用 或 進行進一步開發:
📌 GitHub 倉庫:MILS on GitHub
📌 技術論文:arXiv 論文
目前 MILS 正在快速發展,未來將可能改變 AI 多模態處理的標準方式,成為 LLM 智慧推理與跨模態生成的重要技術。
總結
MILS 讓 AI 獲得強大的多模態能力,且無需重新訓練,能夠應用於 內容生成、AI 推理、智慧推薦等多種領域。
這項技術的出現,代表未來的 AI 模型將能更輕鬆地理解和創造多模態內容,進一步推動 AI 在 智慧媒體、創意設計、智能交互 等領域的發展。 🚀
常見問題與解答(FAQ)
1. MILS 和其他多模態 AI 技術有什麼不同?
MILS 的最大特點是 無需額外訓練,它透過 多步推理(Iterative Reasoning)與反覆優化,讓 LLM 能夠處理圖像、音訊、影片等多模態任務。相比傳統方法,它不需要大量標註數據,且適用於各種 LLM,讓多模態 AI 更容易部署與應用。
2. MILS 可以在哪些領域應用?
MILS 適用於 社交媒體內容生成、AI 內容檢索、智能推薦、視覺問答、多模態 RAG(檢索增強生成) 等場景。例如,它可以用來 自動產生社群貼文的圖像描述、提升 AI 內容推薦精準度、幫助智慧助手理解視覺與音訊資訊,甚至能用於 創意設計與數位藝術 領域。
3. MILS 是否適用於所有 LLM?
是的!MILS 不依賴特定的 LLM,而是透過 提示工程(Prompt Engineering)與評分機制 來強化現有語言模型的多模態處理能力。這表示,它可以與 GPT-4、LLaMA、Claude 等各種 LLM 搭配使用,而不需要對這些模型進行額外訓練。
成為AI學習平台訂閱者

NT$300 / 1個月

NT$900 / 3個月

NT$3,000 / 12個月