Zmo.ai AI 圖像生成與編輯工具完整指南高效打造專業級視覺內容
Zmo.ai AI 圖像生成與編輯工具完整指南高效打造專業級視覺內容
Zmo.ai 是一款集成多種 AI 圖像生成與編輯功能的智能平台,無需使用者具備美術或設計基礎,即可輕鬆創建各類圖像。該平台支援使用文字描述或上傳圖片來生成和編輯圖像,提供多種 AI 工具,如 AI 照片生成器、AI 動漫生成器、AI 照片編輯器、AI 背景更換器和 AI 視頻生成器。
Zmo.ai 是一款集成多種 AI 圖像生成與編輯功能的智能平台,無需使用者具備美術或設計基礎,即可輕鬆創建各類圖像。該平台支援使用文字描述或上傳圖片來生成和編輯圖像,提供多種 AI 工具,如 AI 照片生成器、AI 動漫生成器、AI 照片編輯器、AI 背景更換器和 AI 視頻生成器。
ShipAny 是專為快速構建 AI SaaS 創業專案而設計的 NextJS 範本工具。它提供生產就緒的範本、強大的基礎設施以及一鍵部署功能,讓開發者與創業者能夠在數小時內完成從想法到產品的轉變。ShipAny 的核心優勢在於快速啟動和高效部署,讓使用者可以在短時間內完成工作原型並推向生產環境。除此之外,ShipAny 內建身份驗證、支付處理、資料存儲與 AI 集成,還支援 SEO 友好結構與國際化,適合全球市場應用。
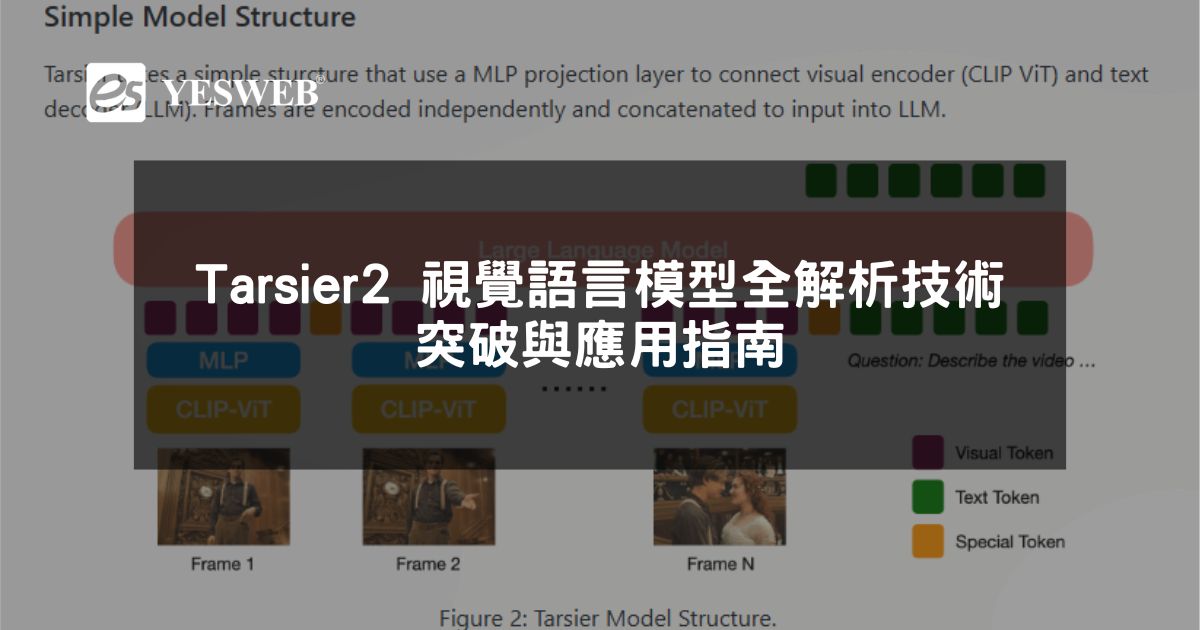
Tarsier2 是由位元組跳動(ByteDance)推出的最新一代大規模視覺語言模型(LVLM),專為理解和描述視頻內容而設計。這款模型能夠生成詳細且準確的視頻描述,在多種視頻理解任務中表現卓越,並在多項基準測試中超越了 GPT-4o 和 Gemini-1.5-Pro。 Tarsier2 的核心功...
Heyboss 是由 Heeyo 推出的一款 AI 程式設計工具,旨在讓任何人都能無需編寫代碼即可開發 AI 應用、網頁、網站甚至遊戲。這款工具被譽為「普通人的 AI 工程師」,幫助用戶將創意迅速轉化為可運行的數位產品。透過簡單的對話方塊輸入想法或上傳相關文件,Heyboss 就能自動完成設計與開發,真正實現「零代碼」開發。它支援多模態功能,涵蓋設計、產品需求、前後端交互、運維與資料庫管理等,適合個人創作者、小型企業與專業開發者使用。

Stable Diffusion Web UI 提供了強大的腳本功能,讓你能更精確地控制圖片生成。本篇介紹三個常見的腳本:「提示詞矩陣」可同時測試多組提示詞,快速對比不同風格;「從文字方塊或檔案載入提示詞」能批量生成多張圖片,省去手動輸入的時間;「X/Y/Z 圖表」則可測試不同參數設定,如 CFG Scale、取樣步驟與採樣器,幫助優化出圖效果。此外,還有各種實用的按鈕,可用於存圖、打包、放大與圖生圖調整。學會這些功能,能讓你的 AI 圖片創作更加高效且精準!
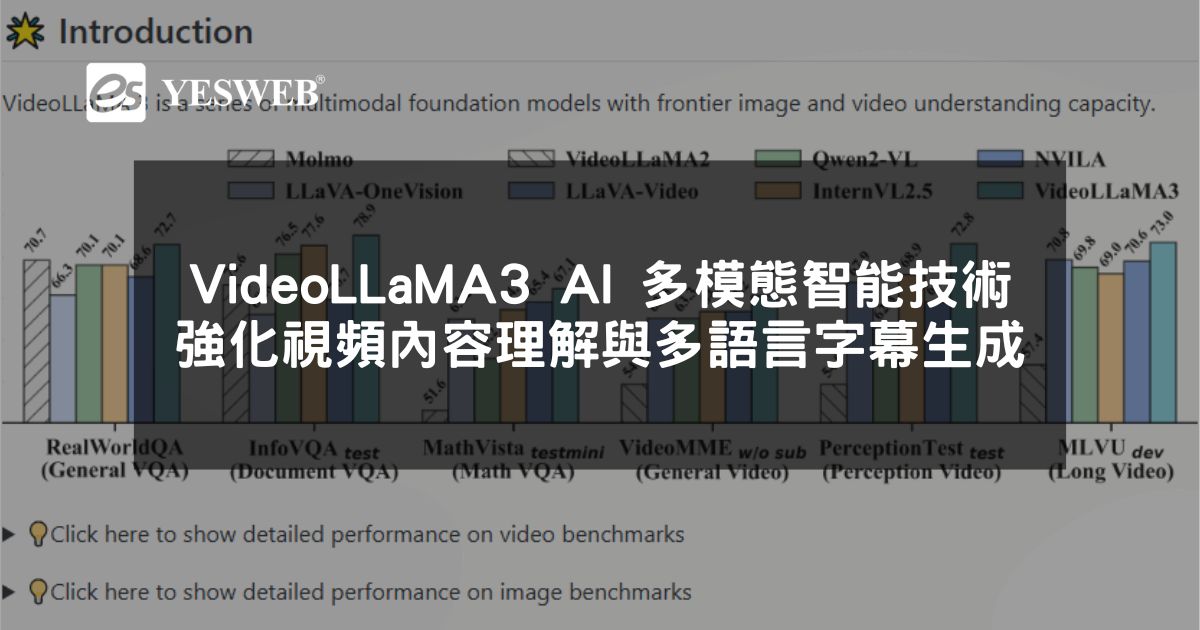
VideoLLaMA3 是 阿里巴巴開源 的 前沿多模態 AI 模型,專注於 圖像與視頻理解,具備 視頻內容分析、視覺問答、多語言支援 等強大功能。該模型基於 Qwen 2.5 架構,結合 視覺編碼器 SigLip 與強大的 語言生成能力,能夠高效處理 長視頻序列,適用於 多模態內容分析與自動字幕生...
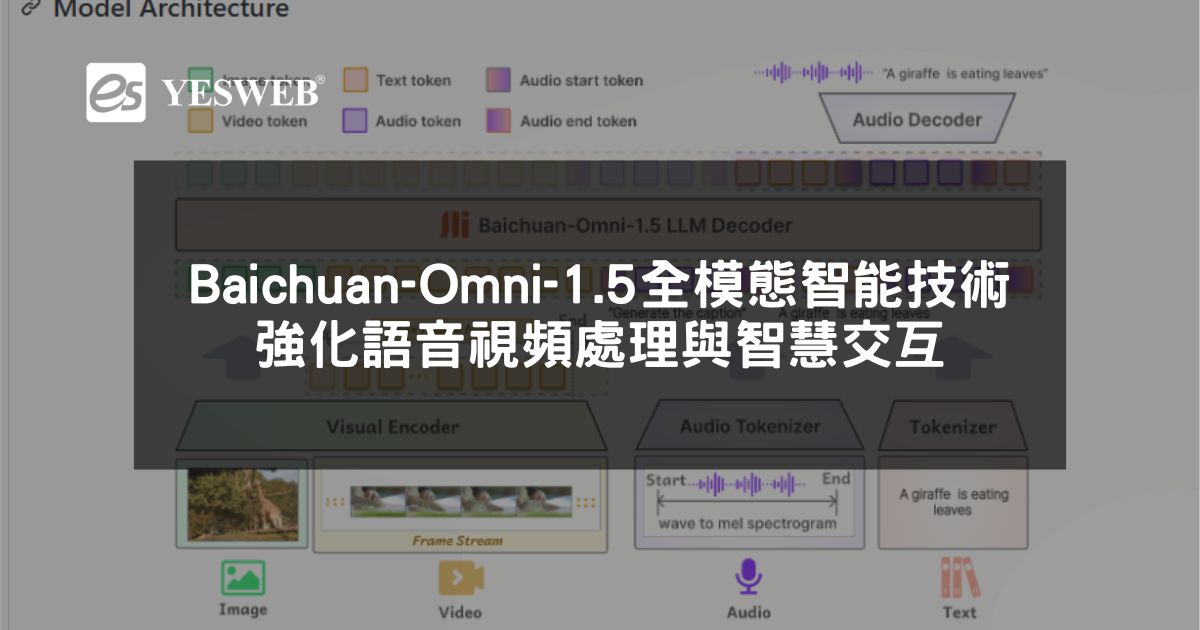
Baichuan-Omni-1.5 是 百川智能 推出的 全模態 AI 模型,支援 文本、圖像、音訊與視頻的全面理解,並具備 文本與音訊的雙模態生成能力。該模型在 視覺處理、語音技術、多模態流式交互 等方面表現優異,尤其在 醫療領域、智慧交互、教育輔助 等應用場景中展現出色實力。
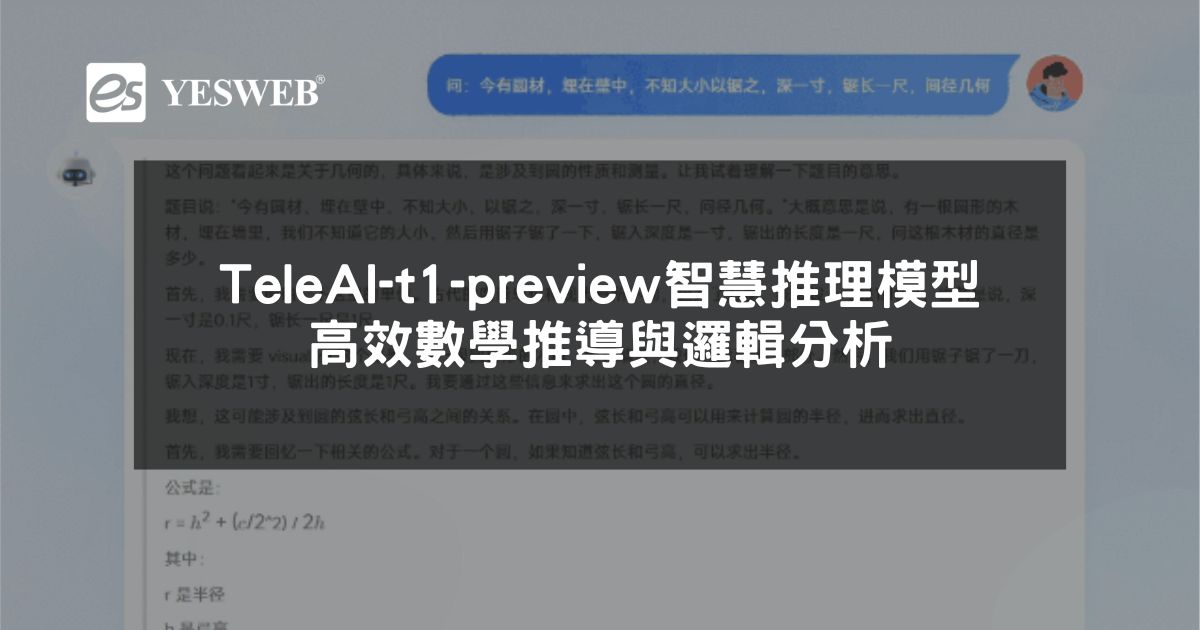
TeleAI-t1-preview 是 中國電信人工智慧研究院 發佈的 複雜推理 AI 大模型,具備 強大的數學推導與邏輯推理能力,透過 強化學習與思考範式 提升解題精度,在 數學競賽、學術研究、策略分析 等領域表現突出。 本篇文章將詳細介紹 TeleAI-t1-preview 的核心功能、技術優勢...

Qwen2.5-1M 是阿里通義千問團隊推出的 開源大型語言模型(LLM),支援 100萬 Tokens 的超長上下文處理能力。這款模型相較於其前代 128K 版本,在處理 超長文本、複雜語境理解 方面表現優越,特別適用於 學術研究、內容創作、數據分析 等應用場景。 本篇文章將深入介紹 Qwen2....

Recap 是一款基於 大型語言模型(LLMs) 開發的智慧工具,專為快速理解和總結各類內容而設計。無論是 文本、網頁、PDF、影片,Recap 都能迅速提取關鍵資訊,並生成簡潔、易讀的摘要。同時,它還支援 多語言翻譯與內容創作,大幅提升學術研究、職場工作、內容創作等領域的效率。 在這篇文章中,我們...