VideoChat-Flash 是由上海人工智慧實驗室與南京大學等機構聯合開發的一款專門針對長影片建模的多模態大語言模型(MLLM)。該模型通過創新的 分層壓縮技術(HiCo),顯著減少計算量,同時保留關鍵資訊,能夠高效處理長達數小時的影片內容,提升對長影片的理解能力。
VideoChat-Flash 的主要功能

1. 長影片理解能力:高效處理長達數小時的內容
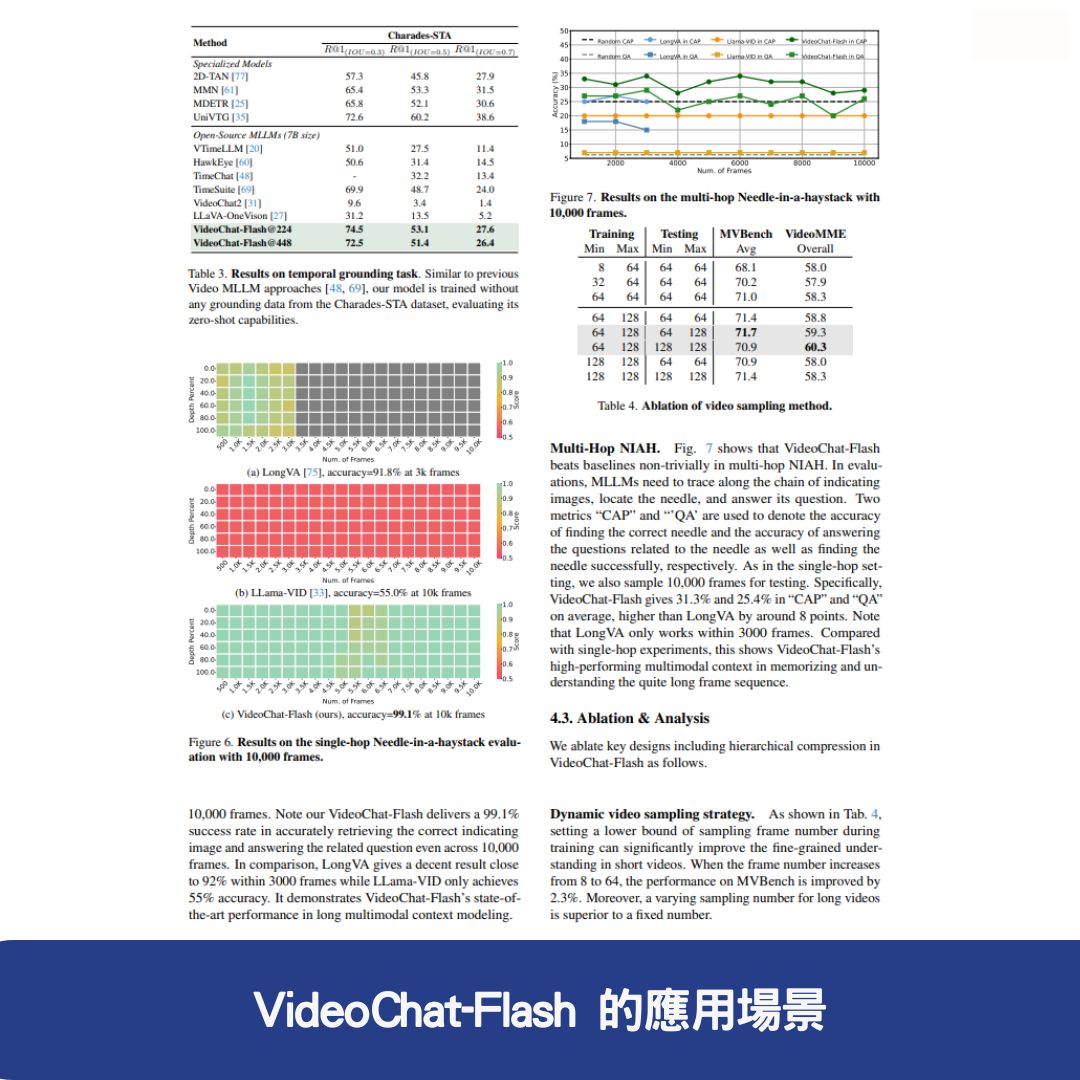
VideoChat-Flash 透過 分層壓縮技術(HiCo),能夠高效處理長影片,並在 “針在乾草堆中”(NIAH) 任務中實現 99.1% 的準確率,成為首個能夠處理 10,000 幀(約 3 小時影片)的開源模型。
2. 高效模型架構:計算量降低,推理速度提升
模型將 每個影片幀壓縮為僅 16 個 token,相比前代模型,推理速度提升 5-10 倍,使其在長影片處理領域表現優異。
3. 強大的影片理解能力:超越其他 MLLM 模型
在多個長影片與短影片基準測試中,VideoChat-Flash 超越了其他開源 MLLM 模型,甚至在某些任務中表現優於規模更大的模型。
4. 多跳上下文理解:提升對複雜內容的解析能力
支援 多跳 NIAH 任務,能夠追蹤長影片中的 多個關聯圖像序列,進一步提升模型的 上下文理解能力,適用於監控分析、體育影片解析等場景。
VideoChat-Flash 的技術原理

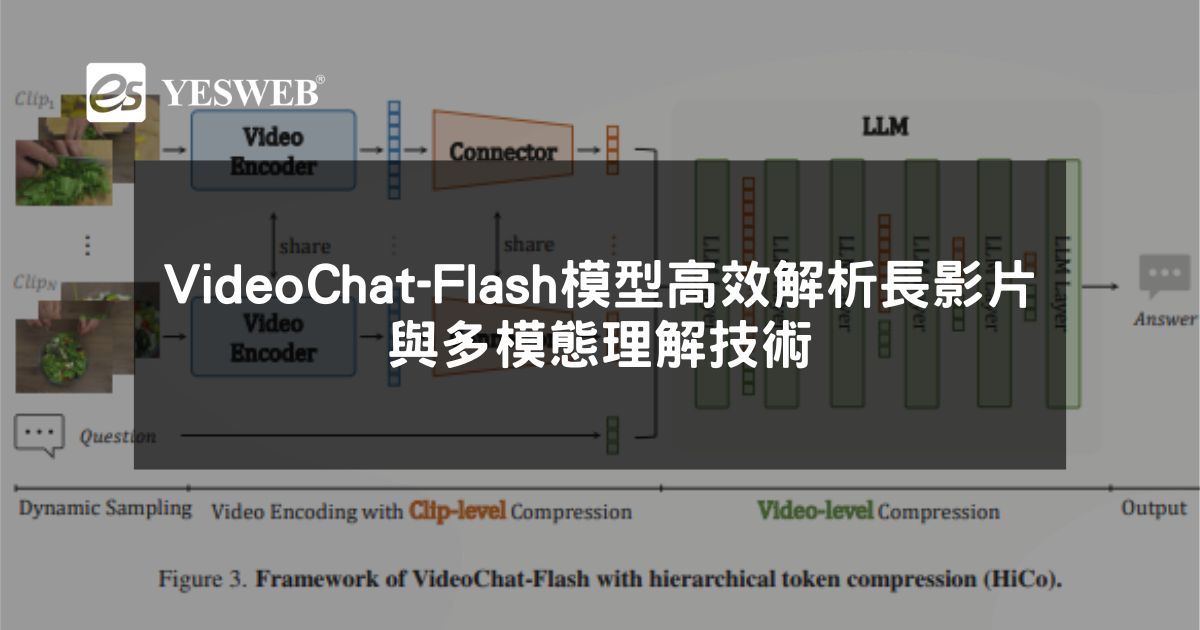
1. 分層壓縮技術(HiCo):處理冗餘視覺資訊
VideoChat-Flash 的核心技術之一是 HiCo(Hierarchical Compression),旨在減少長影片中的冗餘資訊,提升模型的運算效率。
- 片段級壓縮:將長影片分割為較短片段,獨立編碼。
- 影片級壓縮:在片段基礎上進一步壓縮整個影片的上下文,減少 token 數量。
- 語義關聯優化:根據使用者查詢的語義資訊,減少不必要的視覺標記。
2. 多階段學習方案:提升長影片理解能力
VideoChat-Flash 採用 從短到長的多階段學習策略,確保模型能夠適應不同長度的影片內容。
- 初始階段:利用短影片進行監督微調,建立基礎理解能力。
- 擴展階段:引入長影片數據,提升對更長上下文的解析能力。
- 混合語料訓練:使用短影片與長影片混合訓練,實現全面適應。
3. LongVid 資料集:為長影片理解提供強大支持
為了支援模型訓練,研究團隊構建了 LongVid 資料集,其中包含 30 萬小時的長影片 和 2 億字的注釋,為 VideoChat-Flash 提供了豐富的學習素材。
4. 模型架構:視覺編碼器 + 視覺-語言連接器 + LLM
VideoChat-Flash 採用 三層架構,包括:
- 視覺編碼器:將影片幀轉換為壓縮標記。
- 視覺-語言連接器:建立視覺與語言之間的聯繫。
- 大語言模型(LLM):進行長上下文建模,提升理解能力。
VideoChat-Flash 的應用場景
1. 影片字幕生成與翻譯
能夠根據長影片生成詳細且準確的字幕,適用於 多語言翻譯 和 無障礙字幕生成,幫助觀眾更好地理解內容。
2. 影片問答與互動
支援 基於影片內容的自然語言問答,使用者可以透過提問獲取 電影劇情解析、紀錄片知識點 等資訊。
3. 具身 AI 與機器人學習
在 具身 AI 領域,VideoChat-Flash 可透過 長時間自我視角影片 幫助機器人學習 複雜任務,例如製作咖啡、家務處理等。
4. 體育影片分析與集錦生成
能夠 分析體育比賽影片,提取 關鍵賽事瞬間,自動生成 比賽集錦,提高觀眾觀看體驗。
5. 監控影片分析
適用於 長時間監控影片分析,能夠 識別與追蹤關鍵事件,提升監控系統的效率與準確性。
VideoChat-Flash 的項目位址
- GitHub 倉庫:VideoChat-Flash
- arXiv 技術論文:arXiv PDF
為何選擇 VideoChat-Flash?
- 高效處理長影片:能夠處理數小時長影片,超越其他 MLLM 模型。
- 創新 HiCo 技術:減少冗餘資訊,提升模型效率。
- 多階段學習方案:從短到長的學習方式,確保適應各種影片長度。
- 廣泛應用場景:涵蓋 字幕生成、體育分析、機器人學習 等領域。
VideoChat-Flash 是 未來 AI影片理解技術的關鍵突破,適用於多種影片處理場景,讓長影片理解變得更加高效智能!
常見問題與答覆
1. VideoChat-Flash 能處理多長的影片內容?
VideoChat-Flash 可處理長達 數小時 的影片內容,並透過 分層壓縮技術(HiCo),有效降低計算量,同時保留關鍵資訊,使其在長影片分析上具備高效能。
2. VideoChat-Flash 與其他影片理解 AI 模型有何不同?
與傳統 MLLM 模型相比,VideoChat-Flash 採用 HiCo 技術與多階段學習方案,能夠處理超長上下文,並在 “針在乾草堆中”(NIAH) 任務中達到 99.1% 準確率,超越多數開源 AI 模型。
3. VideoChat-Flash 可應用於哪些場景?
VideoChat-Flash 適用於 自動字幕生成、影片問答、機器人學習、體育比賽分析、監控影像處理 等多種領域,能夠提升長影片內容的解析與應用效率。
成為AI學習平台訂閱者

NT$300 / 1個月

NT$900 / 3個月

NT$3,000 / 12個月


