
Qwen2.5-1M 是阿里通義千問團隊推出的 開源大型語言模型(LLM),支援 100萬 Tokens 的超長上下文處理能力。這款模型相較於其前代 128K 版本,在處理 超長文本、複雜語境理解 方面表現優越,特別適用於 學術研究、內容創作、數據分析 等應用場景。
本篇文章將深入介紹 Qwen2.5-1M 的核心特性、技術優勢及實際應用場景,幫助讀者更好地理解並使用這款強大模型。
Qwen2.5-1M 的核心功能

Qwen2.5-1M 具備強大的 AI 運算能力,能夠 精確處理長篇文本,其主要功能包括:
1. 超長上下文處理能力
Qwen2.5-1M 支援高達 100 萬 Tokens,遠超過傳統 AI 模型的 128K 限制,能夠:
- 一次性處理長篇小說或多篇論文,提升資訊整合能力。
- 準確檢索關鍵資訊,例如在 100 萬 Tokens 內的 Passkey Retrieval 測試中表現出色。
2. 卓越的性能優勢
Qwen2.5-1M 在多個測試資料集中擊敗 GPT-4o-mini,其中 14B-Instruct-1M 版本更是超越 Qwen2.5-Turbo,展現出卓越的 AI 知識理解與應用能力。
3. 短文本與長文本兼容
即便是超長文本專家,Qwen2.5-1M 在短文本處理上仍保持與 128K 版本相當的水準,確保基礎能力不受長序列處理影響。
Qwen2.5-1M 的技術原理

1. 長上下文訓練策略
Qwen2.5-1M 採用了 逐步擴展上下文長度 的方法,確保訓練穩定性,主要分為三個階段:
- 預訓練階段:從 4K 開始,逐步擴展到 256K,並應用 Adjusted Base Frequency,將 RoPE 基礎頻率提升至 10,000,000。
- 監督微調階段:
- 第一階段:針對 短指令(32K 以下) 進行調整。
- 第二階段:混合短指令與長指令(256K)進行訓練。
- 強化學習階段:透過 8K 短文本訓練,確保短文本與長文本之間的能力不會失衡。
2. 稀疏注意力機制
Qwen2.5-1M 採用了 MInference 稀疏注意力優化,提升計算效率,包含:
- 分塊預填充:將輸入序列分塊處理,減少顯存消耗。
- 長度外推方案(DCA):重新映射超長序列中的相對位置,提高長文本處理準確性。
- 稀疏性優化:針對 100 萬長度序列 進行優化,降低精度損失。
Qwen2.5-1M 的應用場景

Qwen2.5-1M 可應用於 學術研究、內容創作、資料分析等多個領域,提升 AI 在不同場景下的效能。
1. 學術研究與論文閱讀
- 同時處理多篇學術論文,快速擷取關鍵資訊。
- 自動標註、生成摘要,幫助研究人員提高效率。
2. 長篇小說與文學創作
- 一次性處理 10 本長篇小說,分析文本結構與角色關係。
- 提供寫作靈感,輔助作家創作高品質內容。
3. 廣告文案與行銷內容生成
- 自動產生吸引人的廣告文案,提升行銷轉換率。
- 分析市場趨勢,根據長期數據變化調整策略。
4. 教學輔助與智慧學習
- 幫助學生快速理解複雜概念,例如科學理論、歷史事件等。
- 自動整理筆記與學習重點,提升學習效率。
5. 大規模數據分析與知識管理
- 分析數據報告與研究文獻,協助企業決策。
- 自動化知識整理與分類,提升企業內部數據管理能力。
Qwen2.5-1M 是 AI 長文本處理的領先選擇
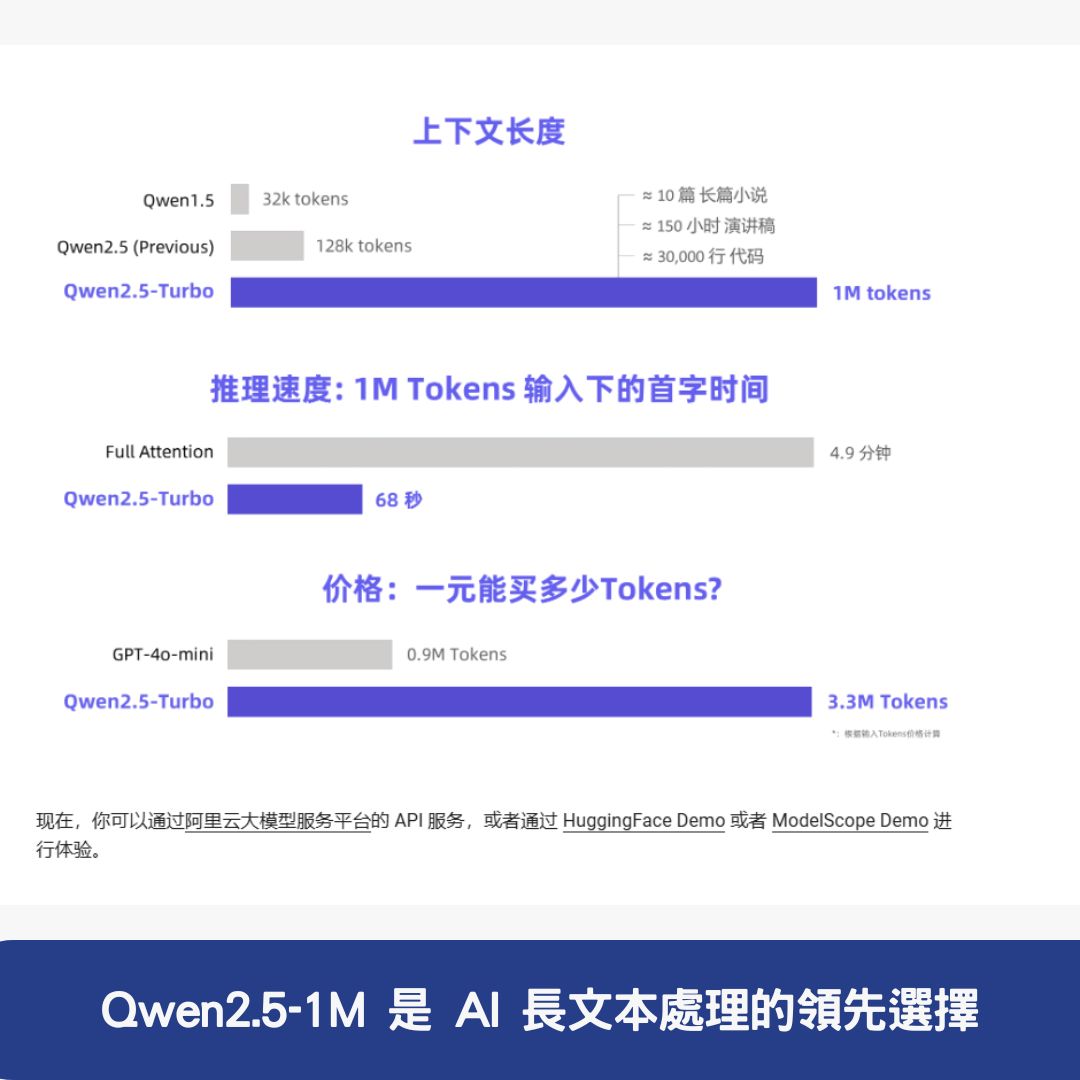
Qwen2.5-1M 憑藉其 100 萬 Tokens 的超長上下文處理能力、強大的性能優勢、兼容短文本與長文本的靈活性,成為學術、內容創作、行銷、數據分析等領域的最佳 AI 夥伴。
如果你需要處理 超長文本內容、進行深度數據分析,或希望利用 AI 提升工作與學習效率,Qwen2.5-1M 無疑是一個值得嘗試的選擇。
🔗 Qwen2.5-1M 官方網站:點此進入 🔗 HuggingFace 模型庫:點此查看 🔗 技術論文:下載閱讀
3 則常見問題與答覆(FAQ)
1. Qwen2.5-1M 與傳統 AI 模型相比,有哪些優勢?
Qwen2.5-1M 具備 100 萬 Tokens 的超長上下文處理能力,大幅超越傳統 128K 模型。此外,它在 長文本檢索、知識整合、數據分析 方面表現出色,並且 在多個測試資料集中擊敗 GPT-4o-mini,展現領先的 AI 處理效能。
2. Qwen2.5-1M 適合哪些應用場景?
這款 AI 模型適用於 學術研究、長篇小說創作、數據分析、行銷內容生成 等領域。例如,研究人員可用它一次處理多篇論文,作家可用它輔助長篇寫作,企業則可利用其分析市場趨勢並產出高效行銷文案。
3. Qwen2.5-1M 是否能同時兼顧長文本與短文本處理?
是的,儘管 Qwen2.5-1M 針對長文本處理進行了優化,它在短文本處理方面仍與 128K 版本相當,確保基本能力不受影響,無論是短指令還是長篇內容,都能保持高效的 AI 運算能力。
成為AI學習平台訂閱者

NT$300 / 1個月

NT$900 / 3個月

NT$3,000 / 12個月


