Qwen2.5-VL 是阿里通義千問團隊推出的開源旗艦視覺語言模型,擁有 3B、7B 和 72B 三種不同規模。該模型在視覺理解、長視頻處理、文檔結構化輸出等方面表現卓越,並具備作為視覺代理(Agent)的能力,能夠執行基本的設備操作。
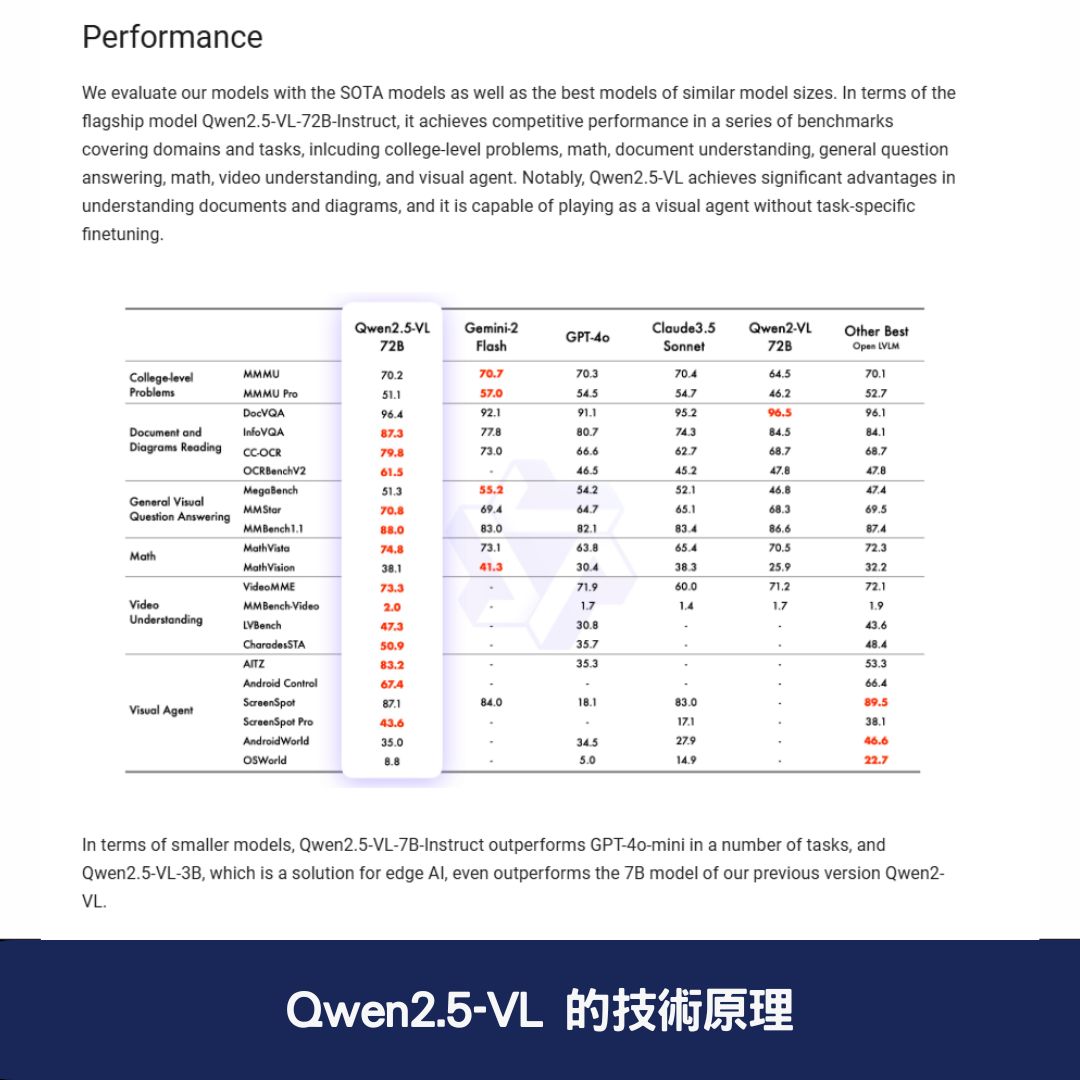
與 GPT-4o-mini 等閉源模型相比,Qwen2.5-VL 在多項測評中展現優越表現,尤其是在文檔與圖表理解方面,提供更精確的分析與資訊提取。
Qwen2.5-VL 的核心功能與優勢

1. 視覺理解與物體識別
Qwen2.5-VL 具備強大的視覺識別能力,能夠識別 常見物體、圖表、佈局 等元素。例如,它可以識別圖片中的花鳥魚蟲,並解析圖像內的文本資訊,提供結構化輸出。
2. 作為視覺代理 (Visual Agent)
該模型能夠推理並動態使用工具,具備初步的電腦與手機操作能力。例如,它可以執行簡單的文件管理、開啟應用程式等動作,這讓 AI 在人機互動方面有了更進一步的突破。
3. 長視頻理解與事件定位
Qwen2.5-VL 可處理超過 1 小時的長視頻,並精準定位重要片段,捕捉關鍵事件。這一功能對於監控分析、影視內容標註等應用場景極為實用。
4. 文檔與表單結構化輸出
該模型能夠解析 發票、表單、表格 等格式,並提供 JSON 格式輸出,適用於金融、法律、企業數據處理等領域。
5. 高效的視覺定位
Qwen2.5-VL 可生成 bounding boxes 或 points 來標記圖片中的物體,並為其座標與屬性提供穩定的結構化數據輸出。
Qwen2.5-VL 的技術原理
1. 模型結構
Qwen2.5-VL 延續 Qwen-VL 的核心架構,採用了 ViT + Qwen2 的串聯結構,並在三種規模的模型中均內建 600M 規模的 ViT,可支援圖像與視頻統一輸入。
2. 多模態旋轉位置編碼 (M-ROPE)
該模型的 M-ROPE 技術將旋轉位置編碼拆解為 時間、空間(高度與寬度)三個部分,使其在處理文本、圖像及視頻時更能夠捕捉位置資訊,提升多模態處理能力。
3. 任意解析度圖像識別
透過 naive dynamic resolution 支持,Qwen2.5-VL 能夠適應不同解析度與長寬比的圖像,使輸入與圖像資訊保持一致,進一步提升模型的適用範圍。
4. 簡化的網路結構
與前一代 Qwen2-VL 相比,Qwen2.5-VL 增強了 時間與空間尺度的感知能力,並簡化了網路結構,使模型效率更高,推理能力更強。
5. 頂尖的推理能力
Qwen2.5-VL 在多個權威測評中獲得最佳成績,特別是在文檔理解和圖表分析領域,超越了許多開源與閉源模型,如 GPT-4o 和 Claude 3.5-Sonnet。
Qwen2.5-VL 的應用場景

1. 文檔與圖表理解
Qwen2.5-VL 具備 優秀的文檔分析能力,可以直接擷取並解析圖表資訊,適用於企業、教育及研究機構。
2. 智能助手應用
作為 智能助手,Qwen2.5-VL 可協助用戶完成各種日常任務,如 預訂機票、查詢天氣、整理資料,提高生活與工作效率。
3. 資料處理與結構化輸出
該模型能夠對 發票、表單、表格 進行結構化分析,適用於 財務報告、企業報表整理、數據自動化處理 等應用。
4. 自動化設備操作
Qwen2.5-VL 具備基本的電腦與手機操作能力,未來有潛力發展為 更智能的 AI 助手,幫助用戶遠端管理設備。
5. 精確的視覺物體定位
該模型能夠生成 bounding boxes 或 points,用於物體識別與場景標註,適合 監控、醫學影像分析、智慧城市等領域。
如何獲取與使用 Qwen2.5-VL?

如果你對 Qwen2.5-VL 有興趣,可透過以下官方管道獲取:
- 官方網站:Qwen2.5-VL 官方部落格
- GitHub 倉庫:Qwen2.5-VL GitHub
- HuggingFace 模型庫:Qwen2.5-VL @ HuggingFace
開發者可以下載模型,並透過 HuggingFace API 或本地部署 來進行測試與應用。
結論
Qwen2.5-VL 是一款強大的 開源視覺語言模型,在 視覺理解、文檔解析、長視頻處理、結構化輸出與視覺代理 等方面均展現優越能力。其技術創新如 M-ROPE、多模態融合、任意解析度識別,使其在多模態 AI 領域中佔據領先地位。
如果你正在尋找一款功能強大的開源視覺語言模型,Qwen2.5-VL 無疑是值得關注的選擇,無論是企業應用、研究開發,還是個人探索,都能帶來優秀的體驗。
常見問題與答覆
1. Qwen2.5-VL 是什麼樣的 AI 模型?
答: Qwen2.5-VL 是阿里通義千問團隊推出的開源視覺語言模型,擁有 3B、7B 和 72B 三種規模。該模型具備視覺理解、文檔結構化輸出、長視頻分析、設備操作等能力,並能夠充當視覺代理 (Visual Agent),在多模態 AI 領域表現卓越。
2. Qwen2.5-VL 主要的應用場景有哪些?
答: Qwen2.5-VL 可以應用於多種場景,包括:
- 文檔與圖表理解:擷取並解析圖表與文件資訊,適合企業、教育及研究機構使用。
- 智能助手:可協助完成日常任務,如預訂機票、查詢天氣、整理資料等。
- 資料結構化輸出:對發票、表單、財務報告等資訊進行結構化整理,提升數據處理效率。
- 設備操作:具備初步的手機與電腦操作能力,可應用於遠端管理與自動化場景。
- 視覺物體定位:透過 bounding boxes 或 points 精準標記圖片中的物體,適用於監控、智慧城市等領域。
3. 如何獲取 Qwen2.5-VL 並開始使用?
答: Qwen2.5-VL 可透過以下官方管道獲取:
- 官方網站:Qwen2.5-VL 官方部落格
- GitHub 倉庫:Qwen2.5-VL GitHub
- HuggingFace 模型庫:Qwen2.5-VL @ HuggingFace
開發者可下載模型,並透過 HuggingFace API 或本地部署 進行測試與應用,進一步探索其強大功能。
成為AI學習平台訂閱者

NT$300 / 1個月

NT$900 / 3個月

NT$3,000 / 12個月