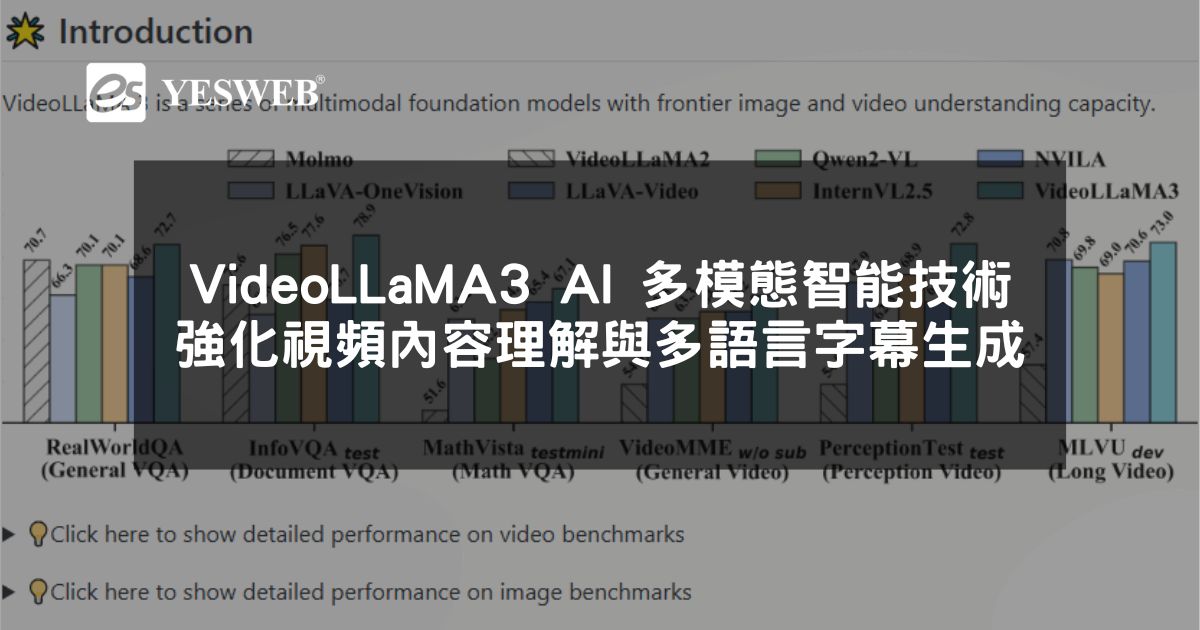
VideoLLaMA3 是 阿里巴巴開源 的 前沿多模態 AI 模型,專注於 圖像與視頻理解,具備 視頻內容分析、視覺問答、多語言支援 等強大功能。該模型基於 Qwen 2.5 架構,結合 視覺編碼器 SigLip 與強大的 語言生成能力,能夠高效處理 長視頻序列,適用於 多模態內容分析與自動字幕生成。
本篇文章將詳細介紹 VideoLLaMA3 的核心技術、應用場景與技術原理,幫助讀者深入了解這款領先的 AI 模型。
VideoLLaMA3 的核心功能
VideoLLaMA3 在 多模態 AI 技術 方面表現卓越,並具備多種 視頻理解與語言生成 能力,以下是其主要功能:
1. 多模態輸入與自然語言生成
- 支援視頻與圖像輸入,生成自然語言描述,幫助使用者快速理解視覺內容。
- 結合圖像與文本輸入進行內容分析與分類,提升多模態應用的性能。
2. 高效的視頻內容分析
- 能深度理解長視頻內容,捕捉細微動作與長期記憶。
- 可自動檢測視頻異常行為,或生成詳細描述,幫助快速理解視頻核心內容。
3. 視覺問答與智能交互
- 根據視頻或圖像輸入的問題,生成準確答案,適用於視覺問答(VideoQA)任務。
- 能夠處理複雜場景,並提供多層次的內容解析與語言回應。
4. 多語言支援與跨語言視頻理解
- 具備跨語言視頻理解能力,支援多語言字幕生成與語言轉換。
- 適用於國際化視頻內容分析與多語言教育應用場景。
5. 流式視頻字幕生成
- 能夠即時生成高品質的視頻字幕,提高視聽輔助體驗。
- 適用於廣播、電影字幕與即時轉錄應用。
VideoLLaMA3 的技術原理
1. 視覺為中心的訓練範式
VideoLLaMA3 採用 視覺為核心的訓練策略,確保模型能夠精準處理 圖像與視頻數據。
- 視覺對齊階段:優化視覺編碼器與投影儀,為模型訓練做準備。
- 視覺語言預訓練:基於大規模 圖像-文本資料(如場景圖像、圖表、文檔)與純文本資料,進行聯合調整。
- 多工微調階段:結合 圖像文本與視頻文本資料 進行訓練,強化視頻理解能力。
- 視頻微調階段:針對視頻理解任務進一步提升模型表現。
2. 視覺為中心的架構設計
- 視覺編碼器能根據圖像尺寸生成相應數量的視覺標記,非固定數量的標記方式使其能夠捕捉更細膩的影像細節。
- 對於視頻輸入,模型能夠減少不必要的視覺標記,提升表示精確性與處理效率。
3. 基於 Qwen 2.5 架構的多模態融合
- VideoLLaMA3 基於 Qwen 2.5 架構,結合 先進視覺編碼器 SigLip,強化 跨模態理解與語言生成能力。
- 能高效處理複雜的視頻與語言任務,適用於 自動標註、視頻分類與場景分析。
VideoLLaMA3 的應用場景
1. 智慧視頻內容分析
- 適用於影視、監控、教育等行業,能自動生成視頻摘要。
- 幫助用戶快速理解長視頻內容,提升影像數據的檢索與管理能力。
2. 視頻問答系統
- 適用於互動式 AI 應用,根據視頻內容回答問題。
- 在教育、娛樂與知識問答領域有廣泛應用。
3. 視頻字幕與內容轉錄
- 能即時生成高品質字幕,適用於影片製作、會議記錄等場景。
- 提升語音轉文本的準確度,適用於新聞、教育等領域。
4. 多語言視頻處理
- 支援多語言轉錄與翻譯,提高跨語言視頻分析能力。
- 適用於國際市場的內容創作者與字幕製作公司。
5. 自動化內容生成與創作
- 根據視頻畫面與文本輸入,生成創意內容與故事情節。
- 適用於 AI 創意寫作、影視製作與新媒體應用。
VideoLLaMA3 引領 AI 視覺與語言理解技術
VideoLLaMA3 憑藉 強大的多模態處理能力、視覺編碼技術與跨語言理解,在 視頻內容分析、視覺問答、字幕生成、智慧教育與影視應用 方面帶來重大技術突破。
如果你希望 提升視頻處理能力、增強視覺問答應用、提高多語言字幕與內容創作效率,VideoLLaMA3 無疑是 最具前景的 AI 解決方案之一。
🔗 VideoLLaMA3 官方資源:
常見問題與答覆(FAQ)
1. VideoLLaMA3 與傳統 AI 模型相比,有哪些優勢?
VideoLLaMA3 採用 Qwen 2.5 架構,結合 先進的視覺編碼器 SigLip,具備 強大的多模態融合能力,能夠處理 圖像與視頻輸入,生成精準的自然語言描述。與傳統 AI 模型相比,它 支援長視頻內容分析、視覺問答、多語言理解,並在 自動字幕生成與跨模態任務處理 上表現優越。
2. VideoLLaMA3 可以用在哪些場景?
VideoLLaMA3 適用於 視頻內容分析、視覺問答、自動字幕生成、多語言教育 等應用場景。例如,它能幫助 影視內容創作者自動產生字幕與摘要,協助 教育領域提供即時字幕與多語言學習支持,並能用於 監控影像分析與異常行為檢測。
3. VideoLLaMA3 的多語言支援如何提升視頻處理能力?
VideoLLaMA3 具備 跨語言視頻理解與字幕生成 能力,能夠自動 轉錄語音內容、生成精準字幕,並提供即時翻譯。這使得它能夠應用於 國際市場、語言學習平台、全球影視字幕製作,讓不同語言的觀眾能夠無障礙理解視頻內容。
成為AI學習平台訂閱者

NT$300 / 1個月

NT$900 / 3個月

NT$3,000 / 12個月


