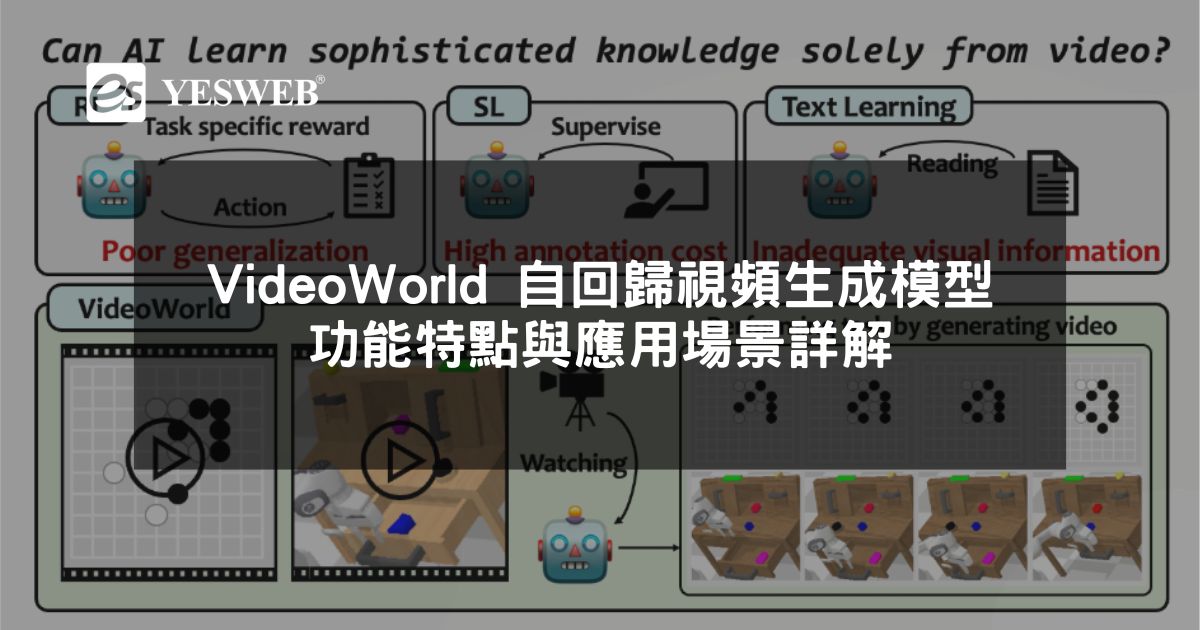
VideoWorld 是由 北京交通大學、中國科學技術大學 和 位元組跳動 聯合開發的一項 深度生成模型研究專案。這項研究旨在探索 是否能僅通過未標注的視頻資料學習複雜知識,例如 規則、推理和規劃能力,而 不依賴於傳統的文本或標注資料。
本文將詳細解析 VideoWorld 的 主要功能、技術原理、應用場景 和 技術優勢,幫助您全面了解這款 自回歸視頻生成模型 的潛力和應用價值。
VideoWorld 的核心功能

VideoWorld 的成功主要源於其 高效的視頻生成與複雜知識學習能力,以下是其五大核心功能:
1. 從未標注視頻中學習複雜知識
- 自主學習規則與推理: VideoWorld 能夠 僅通過未標注的視頻資料,學習 複雜的任務知識,包括 規則、推理和規劃能力,無需依賴 語言指令或標注資料。
- 不依賴強化學習: VideoWorld 不依賴於傳統的強化學習方法(如 搜索演算法或獎勵機制),而是通過 純視覺輸入 自主學習複雜的任務。
2. 自回歸視頻生成
- VQ-VAE 與自回歸 Transformer: VideoWorld 使用 VQ-VAE(向量量化-變分自編碼器) 和 自回歸 Transformer 架構,生成 高品質的視頻幀,並通過 生成的視頻幀推斷出任務相關的操作。
- 連貫的視頻序列生成: 通過 自回歸機制,VideoWorld 根據前面的幀 預測下一幀,生成 連貫且高品質的視頻序列。
3. 長期推理與規劃
- 圍棋任務中的長期規劃: 在圍棋任務中,VideoWorld 能夠 進行長期規劃,例如 選擇最佳落子位置並擊敗高水準對手(如 KataGo-5d),展示了其 高效的推理和決策能力。
- 機器人任務中的操作序列規劃: VideoWorld 還能夠 規劃複雜的操作序列,完成 多種機器人控制任務,顯示出 卓越的長期推理和決策能力。
4. 跨環境泛化能力
- 知識遷移與泛化: VideoWorld 能夠 在不同的任務和環境中遷移所學的知識,表現出 良好的泛化能力,例如 從圍棋任務遷移到機器人操作任務。
5. 緊湊的視覺資訊表示
- 潛在動態模型(LDM): VideoWorld 引入 LDM(潛在動態模型),將 冗長的視覺資訊壓縮為緊湊的潛在代碼,減少 資訊冗餘,提高 學習效率 和 推理性能。
VideoWorld 的技術原理
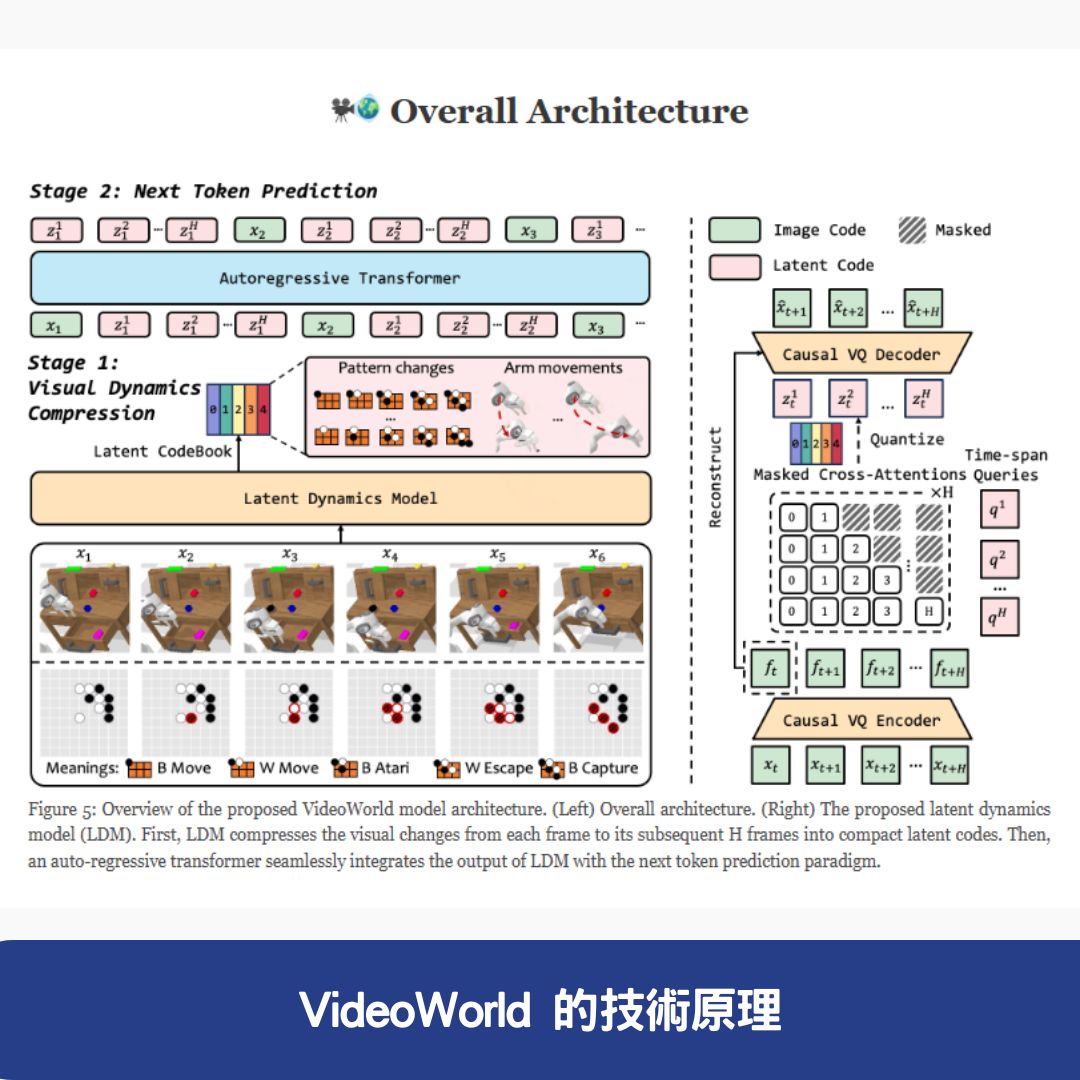
VideoWorld 的成功背後,依賴於其創新的 自回歸視頻生成技術 和 深度學習架構,以下是其主要技術原理:
1. VQ-VAE(向量量化-變分自編碼器)
- 離散 Token 序列表示: VideoWorld 使用 VQ-VAE 將 視頻幀編碼為離散的 Token 序列,通過 向量量化 將 連續的圖像特徵映射到離散的碼本(codebook) 中,生成 緊湊且高效的視覺表示。
2. 自回歸 Transformer
- 下一幀預測: 基於 離散 Token 序列,VideoWorld 使用 自回歸 Transformer 進行 下一個 Token 的預測,生成 連貫的視頻序列。
- 自回歸機制: 自回歸機制 根據前面的幀進行預測,使生成的視頻序列 具備連貫性和邏輯性。
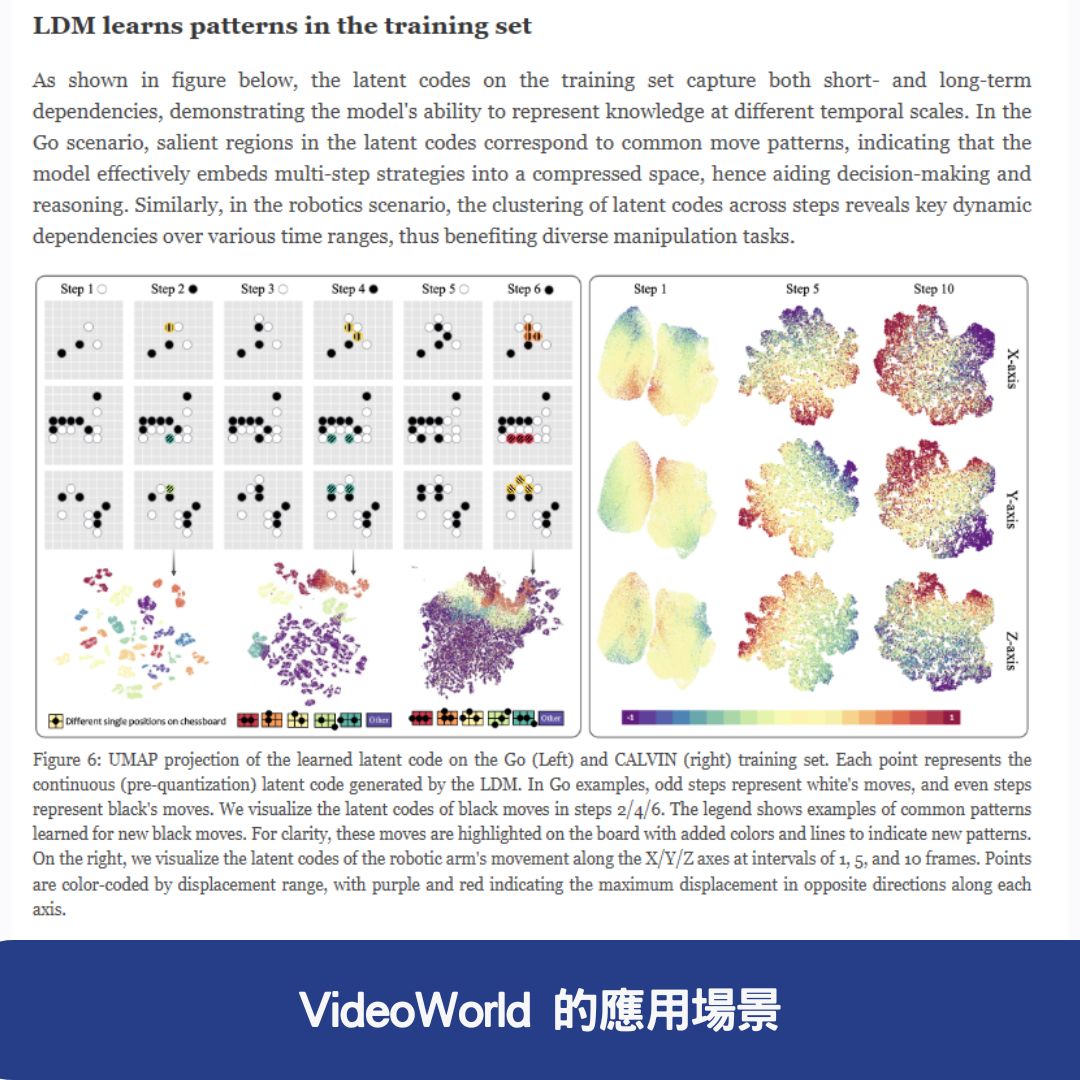
3. 潛在動態模型(LDM)
- 壓縮視覺動態: LDM 將 多步視覺變化壓縮為緊湊的潛在代碼,捕捉 視頻中的短期和長期動態,支援 複雜的推理和規劃任務。
4. 視頻生成與任務操作的映射
- 逆動態模型(IDM): VideoWorld 使用 逆動態模型(Inverse Dynamics Model, IDM),將 生成的視頻幀映射為具體的任務操作。IDM 是 獨立訓練的模組,通常由 多層感知機(MLP) 組成,能 根據當前幀和下一幀預測相應的動作。
VideoWorld 的應用場景
VideoWorld 的強大功能使其在多種應用場景中表現出色,包括:
1. 自動駕駛
- 道路環境動態學習: VideoWorld 可通過 車載攝像頭的視頻輸入,學習 道路環境的動態變化,例如 識別交通標誌、行人和障礙物,提升 自動駕駛的安全性和決策能力。
2. 智能監控
- 異常行為檢測: VideoWorld 通過 觀察監控視頻,學習 正常和異常行為的模式,即時 檢測異常事件,提升 公共安全和監控效率。
3. 遊戲 AI 與對抗策略
- 遊戲規則與策略學習: 通過 觀察遊戲視頻,VideoWorld 可以 學習遊戲規則和環境動態,生成 合理的操作策略,適用於 遊戲 AI 對抗和自動化遊戲測試。
4. 機器人控制與操作規劃
- 複雜操作序列規劃: VideoWorld 能夠 規劃機器人操作序列,完成 複雜的控制任務,如 工業自動化、生產線操作。
結論
VideoWorld 是一款 革命性的自回歸視頻生成模型,憑藉其 自回歸 Transformer、VQ-VAE、LDM 和 IDM 等前沿技術,實現了 從未標注視頻中學習複雜知識 的創新突破。
這款模型展示了 高效的知識學習、長期推理、規劃和跨環境泛化能力,在 自動駕駛、智能監控、遊戲 AI、機器人控制 等多個領域中展現出 廣泛的應用潛力。
VideoWorld 不僅 重新定義了深度學習和視覺生成的邊界,更 開啟了從視覺輸入自主學習複雜任務的新篇章。
常見問題與答覆
Q1:VideoWorld 是什麼?
A1:VideoWorld 是 北京交通大學、中國科學技術大學 和 位元組跳動 聯合研發的 自回歸視頻生成模型。它能 僅通過未標注的視頻資料 學習 複雜的任務知識(如規則、推理、規劃),並 生成高品質的視頻幀,應用於 自動駕駛、智能監控、遊戲 AI、機器人控制 等多個領域。
Q2:VideoWorld 的主要功能有哪些?
A2:VideoWorld 的主要功能包括 從未標注視頻中學習複雜知識、自回歸視頻生成、長期推理與規劃、跨環境泛化能力、緊湊的視覺資訊表示 等。它能 高效學習、推理和決策,且 不依賴於傳統強化學習方法。
Q3:VideoWorld 的應用場景有哪些?
A3:VideoWorld 可廣泛應用於:
- 自動駕駛: 學習道路環境的動態變化,識別交通標誌、行人和障礙物。
- 智能監控: 檢測異常行為,提升公共安全。
- 遊戲 AI: 學習遊戲規則和策略,生成合理操作。
- 機器人控制: 規劃複雜操作序列,應用於工業自動化和生產線操作。
成為AI學習平台訂閱者

NT$300 / 1個月

NT$900 / 3個月

NT$3,000 / 12個月